
阅读笔记:SVF: Interprocedural Static Value-Flow Analysis in LLVM
Introduction
传统的计算过程内值流迭代方法对于大型程序十分昂贵并且拓展性不足。稀疏分析领域的最新研究进展为可扩展且精确地分析大型程序提供了一种有前景的解决方案。为避免在程序的控制流图中进行代价高昂的数据流fact传播,稀疏分析通常按以下步骤执行:
- 先预分析,近似处理分析一个程序的定义-使用链
- 随后通过稀疏地执行数据流分析(仅沿着预计算的链进行细化)
在本文中,我们介绍了 SVF—— 一种通过利用稀疏分析领域的最新进展,为 C 程序提供可扩展且精确的过程间分析的工具。SVF 支持对值流构建和指针分析进行迭代式处理,从而为两者提供不断提升的分析精度。SVF 接受由任意指针分析(如 Andersen 分析)生成的指向信息,并构建过程间内存静态单赋值(SSA)形式,以捕获顶层变量和取地址变量的定义 - 使用链。这些值流可随后用于支持各种形式的程序分析,或使更精确的指针分析(如流敏感分析)能够以稀疏方式执行。
使用LLVM IR作为输入,SVF 有潜力利用 LLVM 的前端来处理(除 C 语言之外)用其他语言编写的程序。
系统设计
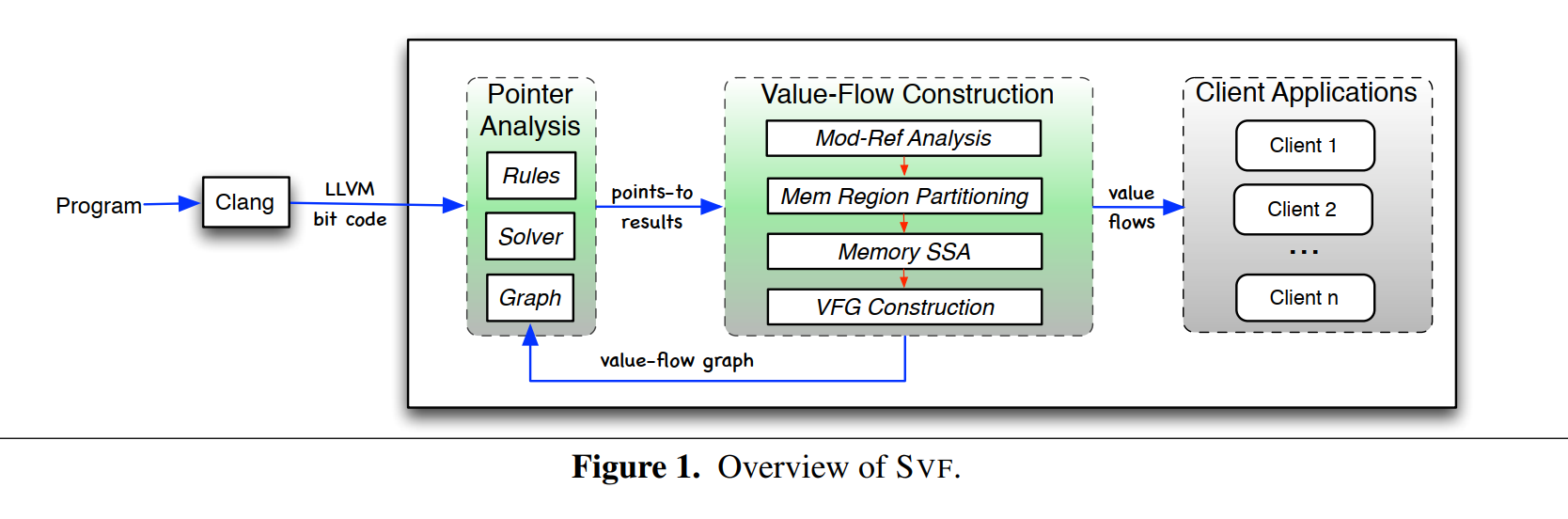
SVF框架如图1所示。程序源代码首先被clang编译成字节码文件,这些文件在链接阶段(LTO)通过LLVM Gold插件合并,生成一个全程序的bc文件。随后“指针分析”模块被激活。基于所获取的指向信息,“值流构建”模块把程序转换为内存静态单赋值(SSA)形式,以便为顶层赋值-使用链和携带地址的变量被区分。这些值流可以被使用于多种客户应用上。
指针分析
指针分析由Graph、Rules和Solver组成。Graph是一个从程序LLVM中间代码中提出的高级抽象,指示应该分析哪一个指针。Rules部分组件定义了如何从每条语句(即图上的每个约束)推导出指向信息。Solver决定了以什么顺序处理所有的限制。
SVF提供了一个干净的、可循环使用的接口给用户来写他们自己的指针分析实现,通过组合这三个组件以一种灵活的方式。Wave [31] 通过在基于包含关系的约束图上应用传递闭包规则 [1] 实现指针分析。类似地,流敏感的指针分析可以通过在稀疏值流图上利用指向传播求解器应用一组流敏感的强 / 弱更新规则来实现。
值流构建
首先来一个轻量级的“Mod-Ref Analysis”来捕捉程序过程间的引用和修改副作用给每一个变量。因此,每个过程中的语句s处的简介定义(使用)都被获取并被表示为Ds(Us)。
”Mem Region Partitioning“ 模块允许用户来分割内存到一组区域中(可能相交),这样可扩展性和准确性平衡可以被完成在分析大型程序中。
语句s被标记上每一个 ,在 ,为了明确在语句 s 处可能被间接定义(使用)的抽象内存对象。
一旦知道了间接使用和定义,”Memory SSA“模块会被唤醒来把程序转换为SSA模块,使用一个标准的SSA转换算法。
最终程序中的值流会被捕捉到一个值流图中通过链接变量的定义和使用,被”VFG Construction“模块完成。
稀疏值流代表
假设不同的抽象内存对象在不同的区域。采用LLVM的转换通过将程序中所有变量的集合 V 分成两个子集合。
- 包含所有可能的目标,例如指针的取地址变量(这些变量的地址被取过了)
- 包含了所有顶级变量,这些变量的地址没有被携带(这些变量不会直接作为指针的目标)
一个稀疏图是直接的图,捕捉了定义使用链上的所有变量。该链准备好当顶级变量以SSA形式。携带地址的变量可以被间接通过load和store指令获取。定义使用链由下面几步构成:
- 程序的指向信息被计算通过使用 Andersen’s 分析。
- 对于加载操作 ,会为每个可能被指针 指向的变量 标注一个函数,以表示在该加载操作处对o的潜在使用。类似地,对于存储操作
*p = q,会为每个可能被指针p ∈ T指向的变量o ∈ A标注o = χ(o),以表示在该存储操作处对o的潜在定义和使用。
如果可以被强更新,那么接收指向的内容,过去里面的内容被清除。否则必须包含其过去内容,导致一个的弱更新。调用点也会用和进行标注(其中),以捕获的过程间使用和定义。相似的,被标记在过程的入口点(出口点)来模仿非局部变量的参数传递(返回)。
- 所有携带地址的变量都会被转为SSA形式,每一个操作被认为是使用,每个操作被认为是定义和使用。
VFG构建
在经过SSA转换并标注了和函数的程序中,其值流图(VFG)通过将每个SSA变量的定义与其使用连接起来构建而成。值流图中的每个节点表示一下内容之一:
- 在非调用语句L处对变量的定义
- 变量定义(直接或间接)作为一个返回值在调用点:
- 一个参数被定义(直接或间接)在程序的入口点

两个节点的边代表(1)一个直接的值流从顶层变量,或(2)一个间接的值流从一个携带地址的变量。表1展示了使用的规则。
COPY规则,含义在位置L处执行赋值操作,建立值流边,表示 “位置 ℓ 处的 p 的值” 来自 “位置 ℓ′ 处的 q 的值”。@ 符号用于关联变量和其所在位置,体现 SSA 中同一变量不同版本的值流动。在q的定义与p的定义连接起来。
PHI规则,SSA 中的 ϕ 指令(合并指令),在位置 ℓ 处,根据程序控制流(比如分支合并),把 v1 或 v2 的值合并给 v3。v3 在位置 ℓ 的值,可能来自 v1 在 ℓ′ 位置的值,也可能来自 v2 在 ℓ′′ 位置的值 ,对应 ϕ 指令处理分支值合并的语义。在的定义和的定义在值流从变量的旧SSA实例和的定义点连接到的定义点。
LOAD规则,在位置 ℓ 处,执行加载操作,从指针 q 指向的内存中读取值,赋给 p。 是前面提到的函数,用于标注指针 q 可能指向的、属于 A 的变量 o(体现潜在的内存访问对象)。含义:加载后,“位置 ℓ 处的 p 的值” 来自 “位置 ℓ′ 处的内存对象 o 的值” ,刻画了从内存对象到加载结果的值流动。间接值流从的定义点连接到的定义点。
STORE规则,含义:在位置 ℓ 处,执行存储操作,把变量 q 的值存入指针 p 指向的内存。 用于刻画内存对象的更新关系(比如 o2 是 o1 被更新后的值,体现内存状态变化 )。含义:存储后,新的内存对象 o2(位置 ℓ 处)的值,一方面来自要存储的变量 q(位置 ℓ′ 处),另一方面关联原内存对象 o1(位置 ℓ′′ 处),体现 “基于旧内存对象 o1,存入 q 的值得到新内存对象 o2” 的语义。
参数传递,从调用点实际参数p的定义点到被调用函数f中形式参数f中对应形参q的定义点,添加一条直接值流边。
返回值传递,从x定义处连接到f函数返回的地方 。
解决对于携带地址变量间接值流概念上和解决对于顶层变量的直接值流一样。
1 | void f(int* ptr) { // 函数 f 接收指针 ptr o3<---o1 |
正如支持上下文敏感分析的标准做法,,调用和返回边在调用点被标记为 和 。因此上下文敏感性可以按照标准方式作为可达性分析来解决,该分析被表述为平衡括号问题,通过匹配调用和返回操作来过滤掉不可实现的过程间路径。
例子
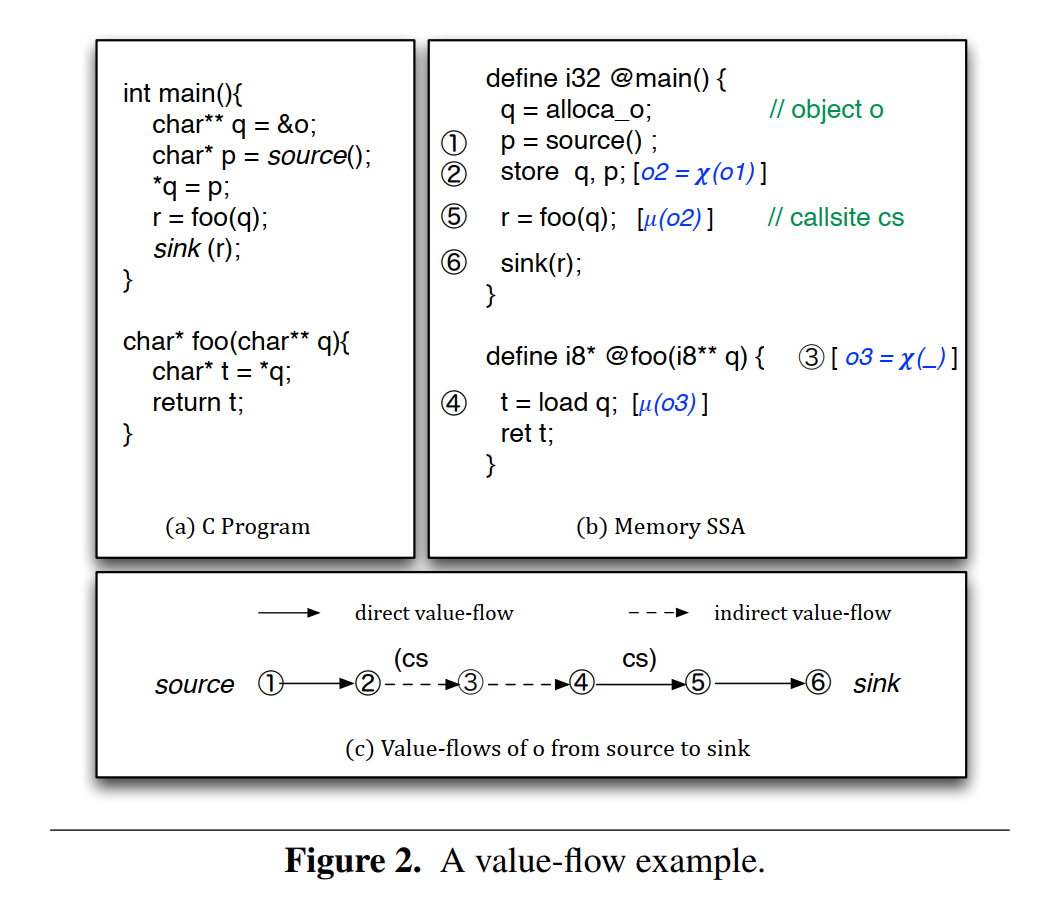
图2(a)展示了一个简单的C程序,图2(b)展示了内存SSA,图2(c)展示了从p定义开始到6的值流图。Andersen的指针分析被首先应用来决定q指向一个对象。随后函数被添加到main和foo的条目里,store代表了o的间接定义, 被添加到调用点,load代表了间接使用o。
使用场景
讨论下面四个使用场景和我们之前过去几年使用SVF的经验。
源-汇分析
许多软件bug检测方法可以被表述为通过值流可达性对其某些源-汇性质进行推理的问题之一。一个典型的应用是内存泄漏检测,包含了检查是否内存分配(源)必须最终到达了释放点在程序的每一个执行路程。
指针分析
加速动态分析
动态分析,通过插桩技术监控程序执行行为,会引入一定的运行时开销。






