
阅读笔记:Which Crashes Should I Fix First Predicting Top Crashes at an Early Stage to Prioritize Debugging Effort
Which Crashes Should I Fix First Predicting Top Crashes at an Early Stage to Prioritize Debugging Efforts
- 使用三个特征分析接下来的top crash
- 使用机器学习
摘要
许多流行的软件系统会自动将故障报告给供应商,使开发人员能够专注于最紧迫的问题。但是,需要一段时间来评估哪些故障发生最频繁。在对 Firefox 和 Thunderbird 崩溃报告数据库的实证调查中,我们发现只有 10 到 20 次崩溃占了崩溃报告的绝大多数;因此,预测这些 “Top crash” 可以显著提高软件质量。通过训练机器学习器了解过去版本中的主要崩溃特征,我们可以在新版本发布之前有效地预测主要崩溃。这样可以快速解决最重要的崩溃,从而改善用户体验并更好地分配维护工作。
引言
当今的任何软件系统都包含自动问题报告功能:一旦出现问题,系统就会将问题详细信息报告给供应商,然后供应商可以利用这些详细信息来解决问题。作为自动问题报告的一个示例,请考虑著名的 Firefox Internet 浏览器。当运行时或操作系统 (OS) 检测到不可恢复的故障(“崩溃”)时,浏览器进程将终止。一个单独的 “talkback” 进程检测到这一点,并要求用户向 Firefox 开发人员提交一份崩溃报告,总结此崩溃事件(图 1)。每个崩溃报告都包含一个崩溃点1,即发生崩溃的程序位置。具有相同崩溃点的崩溃被认为是相同的 [58]。此外,崩溃报告还包括与崩溃发生相关的其他信息,例如用户注释、硬件和软件配置以及线程堆栈跟踪 — 在崩溃时处于活动状态的方法堆栈。
这样提交的崩溃报告数量可能很大:每天,Firefox 用户都会提交数千份崩溃报告;在新软件发布后,这个数字会大幅飙升。然而,这些车祸报告所总结的车祸并不同样频繁。正如我们在本文中所展示的,很可能只有少量车祸占了绝大多数车祸报告。我们将这些崩溃称为顶级崩溃。例如,在 Thunderbird 中,我们发现超过 56.42% 的崩溃报告可以追溯到 20 次崩溃。换句话说,如果我们能提前修复导致这 20 个“主要崩溃”的缺陷,我们就可以将崩溃的发生次数减少 56.42% 或更多。在 Firefox 中,前 20 名崩溃甚至占所有崩溃报告的 78.26%,这意味着只要我们知道要修复哪个缺陷,一点点努力就可以产生很大的收益。因此,尽快识别这些主要崩溃至关重要,这样开发人员就可以确定调试工作的优先级并首先解决主要崩溃。
目前,大多数崩溃报告系统根据其崩溃报告的数量对崩溃进行排序。这些系统可以很容易地用于识别主要崩溃,但只是事后诸葛亮。要确定排名靠前的车祸,必须等待观察,直到提交了足够的车祸报告;这意味着用户必须经历多次崩溃才能获得修复,从而导致可能的数据丢失和挫败感。因此,在本文中,我们研究了预测主要碰撞的策略。具体来说,我们的目标是在第一次发生崩溃时确定崩溃是否是顶级崩溃。此类预测可用于在开发的早期阶段识别主要崩溃,例如,在 alpha 或 beta 测试阶段,此时只有少数崩溃报告可用。这可能使开发人员能够更早地关注主要崩溃,并以更具成本效益的方式提高软件的整体质量。
为了应对这一挑战,我们采用了一种基于学习的方法,如图 2 所示。在早期版本中,我们知道哪些崩溃报告是“top”(频繁)和哪些是“bottom”(不频繁)。我们提取顶部和底部堆栈跟踪及其方法签名。然后,这些签名的特征将传递给机器学习器。然后,学习者可以立即将新传入的崩溃报告汇总的崩溃分类为频繁(最高崩溃)或不频繁。如第 3 节所示,如果开发人员首先修复主要崩溃,那么部署准确的 top 崩溃预测器可能会将 Firefox 3.5 中的崩溃报告数量减少至少 36%。
我们使用崩溃报告和源代码中的功能来训练机器学习器。我们的初步观察和见解使我们专注于构成我们方法核心的三种类型的特征:
- 首先,我们观察到统计特征可以指示崩溃是顶部崩溃还是底部崩溃:特别是,顶部崩溃的堆栈跟踪中的方法再次出现在其他顶部崩溃中。这促使我们从崩溃报告中提取历史特征。
- 其次,方法内特征还可以指示方法是否属于频繁崩溃; 复杂方法可能会更频繁地崩溃。这促使我们采用复杂性指标 (CM) 功能,例如代码行数和路径数,以进行顶部崩溃预测。
- 第三,intermethod 特征可以描述崩溃频率;调用图中连接良好的方法可能会经常崩溃。为了衡量连通性,我们采用了社交网络分析 (SNA) 功能,例如中心性。
为了验证我们的方法,我们调查了 Firefox Web 浏览器以及 Thunderbird 电子邮件客户端的崩溃报告存储库。我们使用一个非常小的训练集,其中仅包含来自先前版本的 150-250 个崩溃报告(即,在发布后 10-15 分钟内收到的崩溃报告)。鉴于该集的大小较小,机器学习器可以立即对新版本的崩溃报告进行分类,即对第一个崩溃报告进行分类。这种分类方法具有很高的准确性:在 Firefox 中,75% 的传入报告都被正确分类;在 Thunderbird 中,准确率上升到 90%。这些准确的预测结果可以为开发人员提供有价值的信息,以便他们确定缺陷修复工作的优先级,在早期阶段提高质量,并改善整体用户体验。
从技术角度来看,本文做出了以下贡献:
我们提出了一种新技术来预测崩溃是否会频繁(“顶级崩溃”)。
我们在 Thunderbird 和 Mozilla 的崩溃报告存储库上评估了我们的方法,证明它可以扩展到现实生活中的软件。
我们证明了我们的方法是有效的,因为它只需要上一个版本中的一小部分训练集。这意味着它可以在开发的早期阶段应用,例如,在 alpha 或 beta 测试期间。
- 我们证明了我们的方法是有效的,因为它可以高精度地预测主要崩溃。这意味着解决预测问题的努力是值得的。
- 我们讨论和调查在哪些情况下我们的方法最有效;特别是,我们研究了崩溃报告的哪些特征对成功预测最敏感。
- 总的来说,我们可以快速解决最紧迫的错误,提高软件稳定性,从而提高用户满意度。
本文的其余部分组织如下:在详细介绍了 Firefox 和 Thunderbird 的崩溃报告(第 2 节和第 3 节)之后,我们详细描述了我们的方法(第 4 节),调查了特征选择 (FS) 和模型构建等核心项目。第 5 节描述了我们对 Firefox 和 Thunderbird 崩溃报告存储库的方法的评估,并介绍了评估结果。第 6 节讨论了我们方法的潜在问题,并确定了对其有效性的威胁。在讨论了相关工作(第 7 节)之后,我们以结论和未来的工作(第 8 节)结束。
本文方法
总览
为了预测排名靠前的崩溃,我们使用了机器学习方法,将之前的排名靠前和排名靠后的崩溃作为训练集。图 2 描述了我们方法的概述。
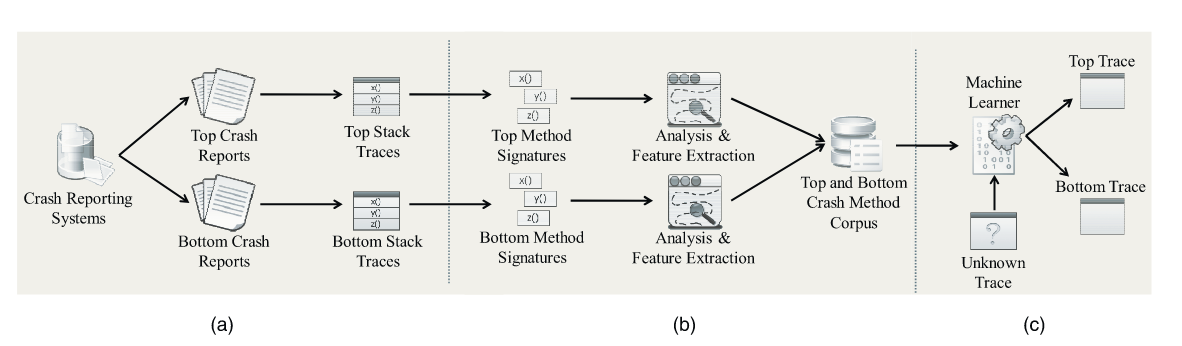
第一步是从 Mozilla 崩溃报告系统(Socorro [54])中提取顶部和底部崩溃,如图 2a 所示。这些崩溃报告来自以前的版本。我们根据车祸数量对它们进行了分类。从提取的崩溃报告中,我们获得了崩溃堆栈跟踪和跟踪中的方法。
第二步是通过分析提取的方法和堆栈跟踪来生成语料库,如图 2b 所示。我们使用三组特征来描述崩溃方法:历史、复杂性指标和社交网络分析特征(第 4.2 节)。然后,我们将每种方法的特征向量转换为(堆栈)基于跟踪的特征向量,因为我们的方法是基于堆栈跟踪的预测(第 4.3 节)。根据基于跟踪的特征向量,我们生成了一个语料库来训练机器学习器。
图 2c 描述了预测步骤。如果有新的崩溃报告,我们会使用三组特征来描述报告中的堆栈跟踪,并将特征向量提供给经过训练的机器学习器。机器学习器预测崩溃是在顶部还是底部。
特征
在本节中,我们将介绍方法级特征:history、CM 和 SNA。为了描述顶部和底部崩溃中的堆栈跟踪,我们考虑了几组特征。首先,我们从早期版本(历史特征)和源代码存储库(CM 和 SNA 特征)的崩溃报告中提取了单独的方法特征数据。然后,我们将特征数据应用于每个方法并生成基于方法的特征向量。
历史特征
我们假设 top crashs 中包含的方法会再次出现在其他 top crashs 中。由于同一软件产品的不同版本通常具有相似的架构和结构,因此我们假设早期版本中报告的 top 堆栈跟踪中的方法在后续版本中经常会再次崩溃。
这一假设受到了错误定位研究 [32]、[40] 的启发。人们普遍认为 bug 的发生是局部的。例如,如果一个方法最近引入了一个 bug,它很快就会引入其他 bug [32]。同样,我们认为我们的历史记录特征反映了堆栈跟踪中崩溃方法的这些特征。
表 1 列出了我们方法中使用的 10 个历史特征。“ count” 功能表示堆栈跟踪中方法的出现次数。“规范化 计数”特征是“ 计数”特征的规范化版本。它们根据每个 “ count” 特征的最大值进行标准化。“* class method” 将方法编码为仅显示在顶部堆栈跟踪中、仅显示在底部堆栈跟踪中或同时出现在两个堆栈跟踪中。功能 “# of crash occurrence” 表示相应方法所属的崩溃报告数。
复杂性指标
我们假设复杂方法比简单方法更频繁地崩溃。因此,我们使用复杂性指标特征(如代码行数和路径数)来表征方法。选择这些功能的灵感来自于 Buse 和 Weimer [11] 在路径执行频率预测方面的工作。根据他们的工作,复杂性指标特征与 “hot paths” 有很强的相关性。
我们使用 Understand C++ [55] 从源代码中提取了 28 个 CM 特征,如表 2 所示。特征包括行数、语句行数、参数数、圈复杂度 [41]、结(重叠循环)[57] 和最大嵌套。面向对象的指标没有被考虑在内,因为我们的大部分主题程序不是用面向对象语言编写的。
社交网络分析功能
复杂性特征捕获了每种方法的内部属性,而社交网络分析特征 [26] 捕获了方法的外部属性,即该方法与其他方法的关系。我们考虑了最常见的关系类型:方法调用。我们的基本观察是,如果崩溃包含许多连接良好的方法,这些方法经常出现在程序的堆栈跟踪中,则崩溃很可能是顶级崩溃。这一观察结果促使我们在预测模型中包含 SNA 特征。
在社交网络分析中,节点的连接程度(在我们的例子中是方法)可以通过许多不同的指标来衡量。在我们的工作中,我们考虑了 5 个,如表 3 所示。请注意,这些指标通常由其他软件工程研究人员使用(例如,[39]、[42]、[59])。为了提取这些 SNA 特征,我们使用 CodeViz [14] 从 Firefox 和 Thunderbird 的源代码构建调用图,以及 Jung [30] 的工作,为调用图中的每个方法推导出这些特征的值。
预测模型
我们的预测模型基于堆栈跟踪,如图 2 所示。例如,假设给定了一个未知的堆栈跟踪 ti。我们的模型预测 t1 是属于 top 还是 bottom crash。因此,我们使用了基于跟踪的特征向量,而不是基于方法的特征向量。
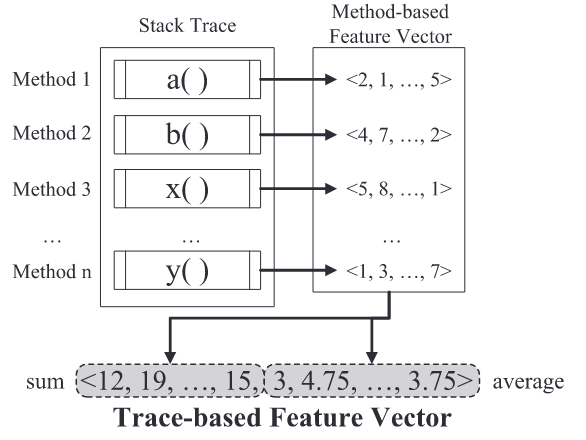
为了获得基于轨迹的特征向量,我们集成了基于方法的特征向量,如图 9 所示。例如,假设崩溃有一个崩溃的堆栈跟踪,其中包括以下方法:[a;b;x;. . . ;y] .这些方法具有单独的特征向量,例如 a=<2;1;. . ;5>, b =<4;7;. . ;2>, x=<5;8;. . ;1> 和 y=<1;3;. . ;>. 然后,我们的方法获得了基于方法的特征向量的每个第 i 个元素的总和。除了总和值之外,我们还获得了每个元素的平均值。由于基于方法的特征向量有 43 个元素(10 个历史特征、28 个 CM 特征和 5 个 SNA 特征),因此基于跟踪的特征向量有 86 个特征(43 个总和特征和 43 个平均特征)。
作为此类特征的一个例子,考虑 CloseRowObject() (顶部崩溃)和 GetDirectoryFromLB() (底部崩溃)两个特征向量,其中这两个崩溃来自 Thunderbird 3.0。在顶部碰撞的特征向量中,“In degree”和“Out degree”特征的平均值分别为 5 和 1.82(总和值为 115 和 42),而在底部碰撞的向量中,这些值分别为 0.2 和 0.34(总和值为 7 和 12)。两次碰撞的“中介中心性”值(平均值)分别为 1.83(顶部)和 0.34(底部)。顶部崩溃比底部崩溃连接到更多的方法,并且位于调用图的最短路径上。这支持了我们的假设,即连接良好的 crash 更有可能是 top crash。
在历史特征组的情况下,这些示例也支持我们的假设。顶部碰撞的 “Top count” 特征的平均值和总和分别为 30.57 和 703,而底部碰撞的平均值和 266 分别为 7.6 和 266。top 崩溃具有其他 top 崩溃中发生的方法多于 bottom 崩溃。这支持了我们的假设,即 top crash 中的 method 可能会再次出现在其他 top crashs 中。
对于复杂性指标特征组之一的 “Cyclomatic” 功能,顶部和底部崩溃分别有 70 次和 14 次。(这些是总和值。平均值分别为 3.04 和 0.4。顶部碰撞比底部碰撞具有更多的线性独立路径。这支持了我们的假设,即复杂方法可能会经常崩溃。
这些示例描述了功能如何描述顶部和底部崩溃的特征。尽管这些示例可能无法完美地描述顶部和底部碰撞的特征,但它们促使我们研究三个特征组。






