
阅读笔记:VFix: Value-Flow-Guided Precise Program Repair for Null Pointer Dereferences
文章解读:VFix——基于值流指导的精准空指针异常修复
1. 研究背景与问题
- 空指针异常(NPE)的普遍性:NPE是Java程序中最常见的错误类型之一,占Mozilla和Apache内存错误的37.2%,Android异常的40%以上。
- 现有APR工具的不足:传统自动程序修复(APR)工具(如HDRepair、ACS、CapGen等)在修复NPE时效率低下,生成的补丁可能存在以下问题:
- 无效补丁(未通过测试用例)或看似合理但错误的补丁(通过测试但逻辑错误)。
- 搜索空间巨大,导致修复耗时(通常需数小时)。
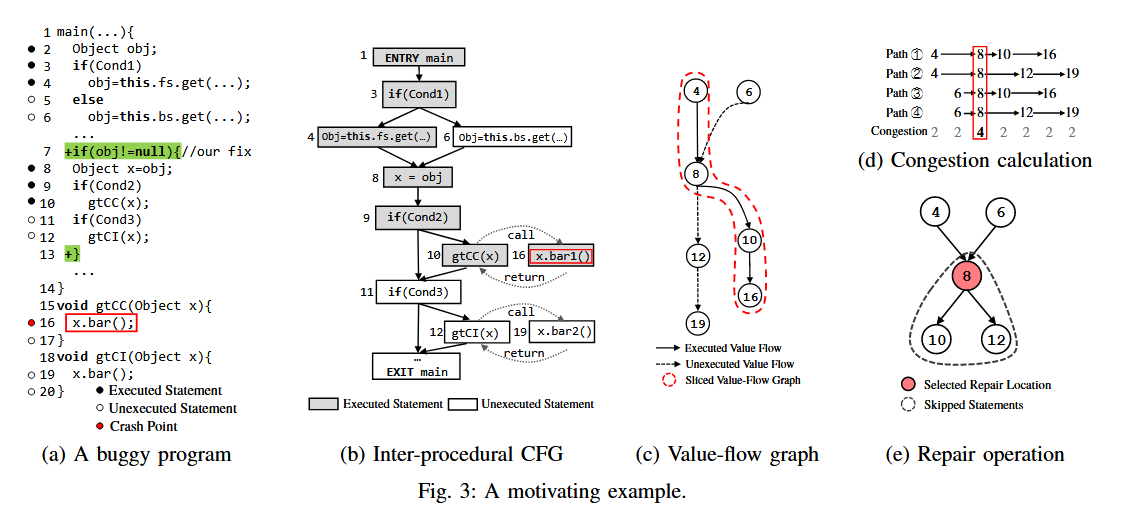
2. VFix的核心思想
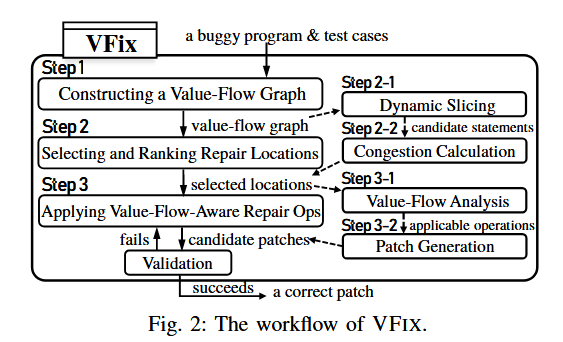
VFix通过值流分析(Value-Flow Analysis) 结合动态执行信息,缩小修复的搜索空间,提高修复的精度和效率。其核心步骤包括:
步骤1:构建静态值流图(Value-Flow Graph, VFG)
- 目标:捕获程序中所有可能导致NPE的变量值传播路径。
- 技术细节:
- 定义-使用关系:分析变量的赋值(如
p = null、p = new T)和传播(如p = q.f)。 - 跨过程分析:通过上下文敏感的指针分析(Context-Sensitive Pointer Analysis)追踪字段和对象在方法间的传递。
- 规则化构建:基于静态切片(Static Slice)生成有向图,节点为语句,边为值流依赖(图4)。
- 定义-使用关系:分析变量的赋值(如
步骤2:选择和排序修复位置
动态与静态结合:筛选出既在静态值流图(
L_sta)中,又在动态执行轨迹(L_dyn)中的语句,得到候选修复位置(L_vf)。拥塞值(Congestion Value)计算:
定义:衡量某条语句在值流图中覆盖的潜在NPE路径比例。
路径枚举:统计从NPE源头(如
p = null)到崩溃点(如p.use())的所有路径,计算各节点的路径覆盖率(图6)。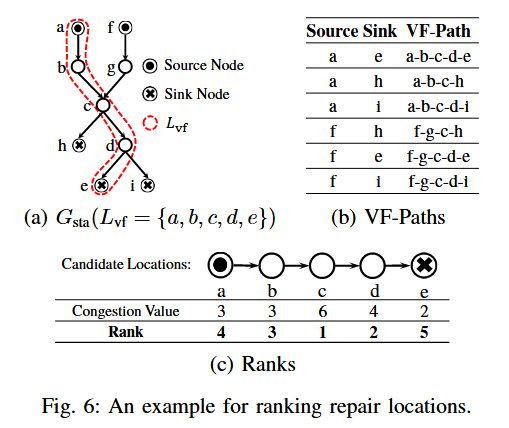
排序策略:拥塞值高的位置优先修复,避免遗漏未触发的潜在NPE。
步骤3:值流感知的修复操作
- 修复模板:基于两种常见NPE场景(变量未初始化、缺少空指针检查)设计修复操作:
- 初始化(Initialization):为可能为
null的变量赋予非空值(如p = new T())。 - 跳过(Skip):插入空指针检查(如
if (p != null)),跳过可能崩溃的代码块。
- 初始化(Initialization):为可能为
- 值流约束:利用值流图过滤无效操作。例如,若修复操作导致后续变量未定义,则放弃该模板(图7)。
3. 实验评估
- 数据集:
- Defects4j:包含15个NPE错误(来自Chart、Lang、Math项目)。
- Apache项目:包含15个NPE错误(来自Pdfbox、Felix等)。
- 对比工具:8种主流APR工具(如SimFix、NPEFix)和运行时恢复工具(如APPEND)。
- 结果:
- 正确性:VFix修复了Defects4j中12个NPE(其他工具最多修复4个),Apache项目中修复12个。
- 效率:平均修复时间从数小时缩短至数分钟,且84%的修复首次生成即为正确补丁。
- 搜索空间缩减:通过值流分析,修复位置数量减少94%,修复操作模板减少57%。
4. 案例分析
- 案例1(Chart-4):修复跨多方法的NPE。VFix通过值流分析确定需跳过的代码块范围,避免过早或过晚闭合
if分支,生成的补丁与开发者手动修复完全一致。 - 案例2(Chart-16):修复未初始化的字段。VFix通过跨过程值流追踪,定位到构造函数中的缺失初始化语句,而非仅修复崩溃点。
5. 局限性与未来工作
- 局限性:
- 目前仅处理变量未初始化和缺少空检查的NPE,未覆盖API误用或类型错误(如整数溢出)导致的NPE。
- 假设程序符合调用图和类型完整性,实际中可能不成立。
- 未来方向:
- 扩展至其他类型错误(如内存泄漏、并发错误)。
- 结合更全面的测试用例生成,进一步提升修复可靠性。
6. 总结
VFix通过静态值流分析与动态执行信息的结合,显著提升了空指针异常的修复能力。其核心贡献在于:
- 精准的故障定位:通过值流拥塞值计算,优先覆盖关键路径。
- 高效的修复生成:基于值流约束过滤无效操作,减少搜索空间。
- 实际有效性验证:在真实项目(Defects4j、Apache)中表现优于现有工具。
该方法为APR领域提供了一种新思路,展示了静态分析在自动化修复中的潜力,尤其适用于复杂依赖和跨过程错误的场景。
构建静态值流图(Constructing Static Value-Flow Slices)
背景和目的
构建静态值流图(Value-Flow Graph, VFG)是 VFix 方法的第一步,旨在通过静态分析捕捉程序中所有可能引发空指针异常(NPE)的代码位置及其相关关系。这一步骤通过分析程序的控制流和数据流,确定变量的定义和使用关系,从而为后续的修复位置选择和修复操作生成提供基础。
静态值流图的定义
静态值流图是一个有向图 Gsta=(Lsta,Esta),其中:
- Lsta 是节点集,表示程序中的语句。
- Esta 是边集,表示变量的定义和使用关系。
值流图通过捕捉变量的定义(def)和使用(use)关系,帮助分析程序中可能引发 NPE 的代码路径。具体来说,值流图包括以下几种边:
- [INTRA-POINTER]:表示同一过程内变量的定义和使用关系。
- [INTRA-OBJECT]:表示同一过程内对象字段的定义和使用关系。
- [INTER-POINTER]:表示跨过程的变量定义和使用关系。
- [INTER-OBJECT]:表示跨过程的对象字段定义和使用关系。
1.3 构建值流图的规则
构建值流图的具体规则如下:
- NULLASGN:
p = null,表示变量p被赋值为null。 - NEWASGN:
p = new T,表示变量p被初始化为一个新的对象。 - COPY:
p = q,表示变量p被赋值为变量q的值。 - LOAD:
p = q.f,表示变量p被赋值为对象q的字段f的值。 - STORE:
p.f = q,表示对象p的字段f被赋值为变量q的值。 - CALL:
p = q.m(−→r ),表示方法调用的结果被赋值给变量p。 - MTDENTRY:
m(−→r ) {},表示方法入口。 - RET:
returnm p,表示方法返回值p。
这些规则通过分析程序的控制流图(CFG)和指针分析结果,确定变量的定义和使用关系,从而构建值流图。
1.4 构建过程
构建值流图的过程如下:
- 初始化:从 NPE 引发的测试用例中获取崩溃点
p.use(),将其作为值流图的初始节点。 - 迭代扩展:通过应用值流图构建规则,逐步扩展值流图,直到达到固定点。具体来说,从初始节点开始,逐步添加所有直接和间接的定义和使用关系。
- 固定点:当值流图不再扩展时,达到固定点,构建完成。
1.5 示例
假设有一个程序片段:
javaCopy
1 | public void example() { |
构建值流图的过程如下:
- 初始化:从
obj的使用点gtCC(obj)和gtCI(obj)开始。 - 迭代扩展:添加
obj的定义点this.fs.get(...)和this.bs.get(...)。 - 固定点:值流图包括所有与
obj相关的定义和使用关系。
1.6 作用
构建静态值流图的作用是:
- 捕捉 NPE 引发的代码路径:通过值流图,可以准确地捕捉到所有可能引发 NPE 的代码路径。
- 确定修复位置:值流图帮助确定哪些语句可能需要修复,从而缩小修复范围。
- 提高修复效率:通过值流图,可以避免在无关的代码路径上浪费时间,提高修复效率。
2. 总结
构建静态值流图是 VFix 方法的第一步,通过静态分析捕捉程序中所有可能引发 NPE 的代码位置及其相关关系。这一步骤通过分析程序的控制流和数据流,确定变量的定义和使用关系,从而为后续的修复位置选择和修复操作生成提供基础。通过值流图,可以准确地捕捉到所有可能引发 NPE 的代码路径,确定修复位置,提高修复效率。
2. 选择和排序修复位置(Selecting and Ranking Repair Locations)
2.1 背景和目的
在构建静态值流图(VFG)之后,下一步是确定哪些语句可能是修复空指针异常(NPE)的关键位置。这一步骤的目标是缩小修复范围,提高修复效率和准确性。通过选择和排序修复位置,可以确保优先修复最有可能导致 NPE 的代码段。
2.2 故障定位问题的公式化
选择和排序修复位置的问题可以公式化为一个图拥堵计算问题。具体来说,给定一个静态值流图 Gsta=(Lsta,Esta),我们需要确定哪些节点(语句)在图中具有最高的拥堵值,即哪些节点在值流路径中出现的频率最高。
- 定义:对于一个源节点 ℓs 和一个汇节点 ℓt,一条 ℓs−ℓt 值流路径(VF-Path)是从 ℓs 到 ℓt 的简单路径。拥堵值 Cℓ 表示节点 ℓ 在所有 ℓs−ℓt 值流路径中出现的次数。
- 计算方法:通过计算每个节点在所有可能的源-汇路径中的出现次数,确定其拥堵值。拥堵值越高的节点越有可能是修复 NPE 的关键位置。
2.3 确定候选修复位置
- 动态切片:结合动态执行信息(如 NPE 触发测试用例的执行路径),确定哪些语句在测试用例中被执行。这些语句构成了动态切片 Ldyn。
- 交集:将动态切片 Ldyn 与静态值流图 Lsta 的交集作为候选修复位置 Lvf。即 Lvf=Ldyn∩Lsta。
2.4 排序修复位置
- 拥堵计算:对于每个候选修复位置 ℓ∈Lvf,计算其拥堵值 Cℓ。拥堵值越高,表示该节点在值流路径中出现的频率越高,越有可能是修复 NPE 的关键位置。
- 排序:根据拥堵值对候选修复位置进行排序。拥堵值越高的节点优先级越高。如果拥堵值相同,则使用逆拓扑排序作为tie-breaker。
2.5 示例
假设我们有一个静态值流图 Gsta 和一个动态切片 Ldyn:
- 静态值流图:包含节点 {a,b,c,d,e}。
- 动态切片:包含节点 {a,b,c,d,e}。
通过计算每个节点的拥堵值,我们得到:
- Ca=3
- Cb=3
- Cc=6
- Cd=4
- Ce=2
根据拥堵值排序,我们得到修复位置的优先级为:c>d>a=b>e。
2.6 作用
选择和排序修复位置的作用是:
- 提高修复效率:通过优先修复最有可能导致 NPE 的代码段,减少不必要的修复尝试,提高修复效率。
- 提高修复准确性:通过选择最有可能的修复位置,减少生成错误补丁的可能性,提高修复准确性。
- 优化资源分配:在有限的资源和时间预算下,优先修复最关键的位置,确保修复过程的高效性。
修复模板
1. 初始化模板(Initialization Templates)
这些模板主要用于初始化可能为空的变量,以防止空指针异常。具体包括以下三种模板:
- [INIT-SIMP]:此模板适用于变量可能为空的情况。它通过运行时的空检查来为变量添加初始化。例如,如果变量
y可能为空,则添加if (y == null) { y = new T(); }。 - [INIT-SRC]:此模板用于修复语句显式地将变量赋值为
null或返回null的情况。它直接为变量添加缺失的初始化。例如,如果语句是y = null,则将其改为y = new T();。 - [INIT-SNK]:此模板适用于因变量
y为空而导致空指针异常的情况。它在变量x(可能因空指针异常而未定义)上添加初始化,并在y为空时跳过该语句。通过添加空检查并跳过相关语句来实现。
2. 跳过模板(Skip Templates)
这些模板通过添加空检查来跳过可能导致空指针异常的语句。具体包括以下三种模板:
- [SKIP-ONE]:此模板用于单个语句可能导致空指针异常的情况。它通过添加空检查来跳过该语句。例如,如果语句
ℓ在y为空时可能导致空指针异常,则添加if (y != null) { ℓ; }。 - [SKIP-MULTI]:此模板用于多个语句可能导致空指针异常的情况。它通过添加空检查来跳过所有依赖于空变量的语句。例如,如果一组语句
FSL(ℓ)在y为空时可能导致空指针异常,则添加if (y != null) { ℓ, ℓ1, ..., ℓn; }。 - [SKIP-RET]:此模板用于通过提前返回来跳过从特定语句开始的所有语句。它在变量为空时添加空检查并返回默认值或
null。例如,如果方法m中的语句ℓ在y为空时可能导致空指针异常,则添加if (y == null) { return; }或if (y == null) { return new T(); }。






