
阅读笔记:Semantic crash bucketing
semantic crash bucketing
- https://github.com/squaresLab/SemanticCrashBucketing
- 确定近似修复识别独特错误的能力
- 分桶+生成近似修复
- 源码级分析
摘要
精确的碰撞分类对于自动化动态测试工具(如模糊测试器)非常重要。在规模上,模糊测试程序会产生数百万个崩溃的输入。模糊测试程序使用启发式方法(如堆栈哈希)来减少重复的错误报告。这些启发式方法很快,但通常不精确:即使在重复数据删除之后,数百个唯一报告的崩溃仍然可能对应于同一个错误。必须手动检查剩余的崩溃,这需要付出相当大的努力。在本文中,我们提出了语义崩溃分桶,这是一种使用程序转换进行精确崩溃分桶的通用方法。语义崩溃分桶将崩溃的输入映射到唯一的错误,作为更改程序的函数(即语义增量)。我们观察到,真正的 bug 修复会精确识别属于同一 bug 的崩溃。我们的见解是通过轻量级程序转换来近似实际的错误修复,以获得相同级别的精度。我们的方法使用 (a) 补丁模板和 (b) 来自程序的语义反馈来自动生成和应用一般错误类别的近似修复。我们的评估表明,近似修复与使用 true 修复进行崩溃存储相比具有竞争力,并且对于三种最先进的模糊测试器,其性能明显优于内置重复数据删除技术。
引言
大规模模糊测试服务的出现,例如 Google 的 OSSFuzz [1, 45] 和 Microsoft 的模糊测试 [9],证明了自动错误查找工具的有效性。当大规模操作时,准确识别独特的错误对于以下方面至关重要:(a) 减少耗时的手动调试工作 [14, 41],(b) 描述自动错误查找工具的有效性 [12, 14, 37, 42, 48],以及 (c) 对有趣的崩溃测试用例进行排名 [14]。但是,有效部署自动模糊测试技术的一个突出挑战是在崩溃分类期间准确识别唯一错误。 模糊测试程序通常会生成数千个崩溃的输入,这些输入最终对应于相同的错误 [14],并且崩溃输入的绝对数量排除了手动检查。这是一个难题,也是一个积极研究的领域 [17]。
自动崩溃分类技术寻求大致存储多个崩溃(但最终等效)输入 [14, 17, 37, 41],以减少工程师必须手动检查的冗余错误报告的数量。在高级别上,模糊测试和符号执行程序等自动化测试工具通常使用特定于工具的启发式分桶策略。研究和行业标准分类技术都有已知的局限性 [17, 42]。技术可以假设 “尽力而为” 的硬编码值(例如,在调用堆栈中要考虑的调用次数 [2]),或者需要针对反馈驱动方法 [3] 的工具特定插桩。这种 Ad Hoc 技术的敏感性各不相同,导致错误识别不精确,这可能以两种方式失败。当由单个 bug 导致的多个崩溃测试错误地归入多个唯一 bug(即重复的 bug 报告)时,就会发生过度近似。当由于多个唯一错误而导致的崩溃测试被放在同一个桶中时 [41, 48] (即,错过唯一错误),就会发生欠近似。
在最新的模糊测试器 [2, 3, 7] 中使用的堆栈哈希 [37, 48] 和分支序列 [7] 技术可能会受到过近似和欠近似 [41, 48] 的影响。此类技术试图将错误唯一性确定为函数,例如,崩溃输入 [48]、程序跟踪 [7, 17]、程序崩溃状态 [3] 或这些的组合 [14]。 最近(以及更复杂的)研究进展提出了使用符号分析 [41]、崩溃输入的机器学习 [14] 和程序跟踪的向后污染分析 [17] 来更精确地分类唯一错误。虽然这些方法通过考虑语义程序行为(例如 [17, 41])来承诺更准确的分桶,但它们的准确性取决于对一般语义特征(例如,符号分支唯一性)的敏感性,并且仍然可能错误分桶错误。内置或硬编码技术进一步难以整合专业知识,从而为错误类别生成更准确的输出。
我们提出了一种全新的方法来识别模糊测试上下文中的唯一错误:通过修改程序本身。我们的见解是,错误可以通过对被测程序的语义转换来表征。例如,在一次执行中修补两个缓冲区溢出中的一个可以区分仅第二个缓冲区溢出特有的崩溃。此外,修复可以阻止相同的逻辑错误出现在多个唯一的执行路径上。
我们的见解借鉴了这样一个事实,即修复程序提供了一种将崩溃输入与独特错误相关联的精确方法,因为正确的修复应该会抵消与相关错误相关的所有导致崩溃的输入。
我们引入了语义崩溃分桶,它将崩溃的输入映射到程序语义中变化 (delta) 的函数,其中 delta 近似于修复错误的根本原因。一般来说,根本原因分析很困难 [27, 39],自动修复 bug 是一个悬而未决的问题 [30]。然而,自动程序修复 (APR) 的现有工作确实表明,程序可以有利可图地进行转换以自动提高质量 [29, 34, 36]。我们方法背后的动机是,使用近似修复更改程序可以准确、自动地限制崩溃行为,以模拟真实的程序修复来检测模糊测试器输出中的独特错误。
语义崩溃分桶与通常的根据正确性 oracle 寻求程序修复(例如测试 [29, 34])的含义形成鲜明对比。但是,尽管语义崩溃分桶的目标与 APR 不同,但它同样会受到过度拟合成功标准的程序转换的影响。例如,假设一个程序包含多个唯一的 bug,每个 bug 都有独立的修复。插入 exit(0);在程序开始时,将满足中和所有崩溃的标准,但会将所有唯一错误与单个修复相关联(并且低于近似值)。因此,为了有效,程序转换必须具有约束语义效果,以精确识别 Semantic Crash Bucketing 下的唯一错误。
我们提出了一种基于规则的方法,使用修复模板来限制崩溃分桶的语义转换。我们的观察是,模糊测试程序通常检测到的常见错误(例如,缓冲区和整数溢出、空取消引用等)具有语义属性,这些属性适合于基于规则的通用修复模板应用(如在模拟 APR 工作中发现,例如 [16, 26, 46])。 在高级别上,基于规则的修复模板应用程序可以将 bug 语义的专业知识集成到分类过程中,以产生更精确的输出。我们演示了 CVE 数据库中实际错误的缓冲区溢出和 null 取消引用的语义崩溃分桶 [4]。缓冲区溢出和空取消引用漏洞是一些最常见的软件安全弱点 [31] 的原因,并且经常通过模糊测试发现 [7, 42, 45]。我们的贡献如下:
- Semantic Crash Bucketing,一种自动识别唯一 bug 的新技术,作为更改程序语义的功能。语义崩溃分桶 通过将程序转换应用于被测程序来对崩溃的输入进行分组。我们使用语义崩溃分桶来识别模糊测试程序中不精确的崩溃报告,并比较开发人员编写的修复程序和近似修复程序的有效性。
- 近似修复。我们提出了一个自动化程序,使用错误修复补丁模板和基于规则的补丁应用来近似正确修复。一般来说,正确和自动修复程序是很困难的。关键的见解是,近似修复的有效性与使用正确的修复来识别独特 bug 相比具有竞争力。我们通过对模糊测试程序常见的实际错误(缓冲区溢出和 null 取消引用)的近似修复来实例化语义崩溃分桶,并演示了有效性。
- 实证评估。我们使用开发人员编写的修复程序比较评估语义崩溃分桶,并使用三种最先进的模糊测试器(AFL-Fuzz [7]、CERT BFF [2] 和 Honggfuzz [3])的重复数据删除技术进行近似修复。我们通过语义崩溃分桶表明,与地面实况修复相比,近似修复将 6 个项目中 21 个错误中的 19 个精确关联(即没有欠近似或过度近似)。我们还表明,使用近似修复进行分桶比所有三个模糊测试器的内置重复数据删除更精确。我们的结果可在线获取。
激励示例
众所周知,AFL-Fuzz 甚至可以在经过充分测试的软件中发现 null 取消引用和内存损坏错误 [5]。考虑在 SQLite 中发现的一个这样的错误:空取消引用,后来由清单 1a 中的补丁修复。sqlite3WalkSelect 函数(第 7 行)遍历 SQL select 语句的表达式树。sqlite3WalkSelect 的返回值可以指示 SELECT …从。。。语句,但未检查返回值。由于 FROM 子句无效,此缺失检查可能会导致在执行期间下游取消引用 null。修复提交消息说:
Make sure errors from the FROM clause of a SELECT cause analysis to abort and unwind the stack before those errors have a chance to mischief in the “*” column-name wildcard expander.
因此,开发人员检查 sqlite3WalkSelect 的返回值并中止,避免下游任何空取消引用(第 8 行,图 1a)。
当前的 fuzzer 和 symbolic executor 可以找到许多不同的崩溃输入,这些 Importing 会触发此类 bug。例如,对导致崩溃的 SELECT…从。。。input 可以遵循不同的调用或分支序列,但仍然会触发相同的 bug。现有技术使用通用启发式方法从一组许多生成的输入中识别唯一的崩溃。调用堆栈哈希 [2, 3, 12, 20, 37] 占主导地位;基于插桩的模糊测试器可以使用对分支序列敏感的程序执行路径 [3]。这些启发式方法快速且有效,但仍然不精确,因为它们对以与实际 bug 无关的方式改变程序执行的输入很敏感。根据启发式和输入,模糊测试程序会将许多重复的崩溃报告为唯一。
我们的方法从程序转换的角度定义了 bug 的唯一性。其动机是,理想情况下,修复错误(如图 1a 中的开发人员所做的那样)可以“捕获”与错误相关的所有崩溃输入,而不管调用堆栈或其他程序执行路径如何。3 挑战在于很难找到真正的修复。自动根本原因分析既困难又昂贵 [27, 33],尤其是对于像这样的错误,需要深入推理。
我们的主要见解是,更简单的近似修复可以替代真正的修复,以精确地对 Bucket 崩溃的输入进行存储。例如,图 1b 显示了针对同一 SQLite 空取消引用错误的自动生成的近似修复。从语义上讲,如果 zSpan 为 null,它会安全地中止程序。事实证明,SQLite 错误直接导致 zSpan 在稍后的程序点(即,当输入语句包含提交消息中描述的 * 扩展器时)为 null。 近似 Patch 精确 “捕获” 与实际 Patch 类似的崩溃输入。
我们的方法使用语法模板和可配置的 “语义提示” 来生成此类补丁。语义提示充当应用补丁模板的谓词。一个具体的例子是“检查程序点 p 处是否有任何解引用的变量为 null。如果是这样,则返回变量名称”。然后,可以使用 specific 变量实例化 patch 模板。通常,每个 bug 类只指定一次补丁生成和应用程序的模板和规则(例如,null 取消引用和溢出)。我们在第 4 节中完整描述了该过程,但在此处提供了 null 取消引用的简要摘要。用于 null 取消引用的 patch 模板检查变量是否为 null,如果为 null,则安全地中止程序。此模板包含一个 “hole” 供变量检查,并且必须使用具体变量进行实例化。我们配置该过程以检查语义提示:使用 debugger 环境在崩溃时变量是否为 null。在这种情况下,我们的过程发现 zSpan[n] 可能是一个有问题的取消引用,并在程序崩溃时动态检查 zSpan 是否为 null。发现变量 zSpan 确实为 null,从而生成图 1b 中的补丁。 验证修补程序以确认修改后的程序不再因输入而崩溃。也就是说,自动生成的补丁有效地近似于真正的修复,因为它会发现并修复在执行过程中在下游触发的相关 null 取消引用,即使它没有深入解决根本原因。
从本质上讲,与典型的重复数据删除启发式方法相比,应用轻量级程序转换通过关注 bug 的语义属性来减少干扰。以每个 bug 类的少量前期成本为代价,我们的方法提供了一种可配置的机制,该机制对 bug 的语义属性很敏感,可以更精确地识别唯一性。
可配置的方法很重要:bug 表现出不同的语义特征,程序转换必须对此敏感。 例如,null 解引用会导致程序立即崩溃,这使我们能够在崩溃时识别可能的原因。 另一方面,缓冲区溢出通常只在访问损坏的内存时才导致崩溃,而不是在实际发生覆盖时发生。因此,处理溢出需要不同的策略(参见 Section 4)。
模糊测试程序还可以低报独特的错误。例如,在简单的调用堆栈方法下,单个函数中的两个唯一 null 取消引用将报告为一个唯一的 bug。我们的技术可以通过独立的程序转换来唯一地识别每个 bug。
语义崩溃分桶
本节介绍语义崩溃分桶 (SCB)。语义崩溃分桶是一种根据程序转换(即语义增量)对崩溃进行分桶的通用方法。语义崩溃分桶可以通过任意程序转换来执行。本节的目标是开发一种方法,与 (a) 真值修复和 (b) 模糊测试器中的现有方法相比,确定近似修复识别独特错误的能力。现在,我们介绍 SCB 的问题定义和应用,用于检测不准确的错误报告。
问题表述
在我们的上下文中,错误是导致错误的软件缺陷(即不良的程序行为);错误是与测试 Oracle 定义的预期行为的偏差。我们讨论了模糊测试程序通常发现的 bug 类型,即那些导致运行时崩溃的 bug。对于此类错误,错误 oracle 由运行时故障发出信号:崩溃导致 SEGFAULT。
语义崩溃分桶 根据程序更改对崩溃的输入进行分组,该更改使这些输入无效(即,导致输入不再使程序崩溃)。因此,唯一 bug 的真正修复会将该 bug 的所有崩溃输入映射到唯一的存储桶。将崩溃分组为已知修复补丁的函数是建立模糊测试崩溃报告的地面实况分类的事实上的方法 [14]。我们使用这个想法来开发一种通用方法来识别由近似修复和模糊测试器引起的错误存储(例如,重复的崩溃报告)。
理想的桶。我们首先定义一个 Ideal Bucketing,其中已知或假定程序中独特错误的正确修复补丁。此定义代表了衡量我们方法有效性的基本事实(第 5 节)。直觉很简单:一些已知或假定的程序转换 Ti 修复了所有与 bug i 相关的崩溃输入,并且只修复了这些输入。 Ti 通过构建理论上理想的 oracle 转换,它正确修复了错误 i 以及它可能导致的所有崩溃行为。在实践中,我们可能会将这种转换视为开发人员针对单个 bug 编写的正确补丁。
我们根据独特的错误、它们引起的崩溃及其修复来表达 Ideal Bucketing。设 i ∈ n 为程序 P 中 n 个唯一 bug 中的唯一 bug i 的标识符。一个唯一的错误 i 与一组一个或多个崩溃的输入相关联,我们用桶 bi 表示。设 Ti : P → P 是一个函数,该函数对程序 P 应用正确的修复,用于唯一错误 i。正确的修复 Ti 修复了由于 i 导致所有导致崩溃的输入 bi,但没有由于输入崩溃的不同错误 j 而导致崩溃的任何崩溃 bj 。
我们将所有包含已知 Ti 、i ∈ n 唯一修复的崩溃输入的桶表示为不相交的分区 B = b1 ⊎ · · ·⊎bn 在 Ti 的正确性假设下。对于特定的 Ti ,理想的分桶意味着:
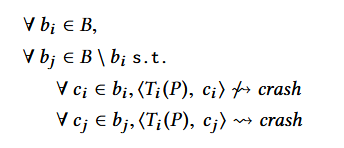
其中 ⟨Ti (P) , c⟩ ̸⇝ crash 表示程序 P 在修复 Ti 的转换下并在崩溃的输入 c 上执行,不会引起运行时崩溃。错误 i 的理想存储桶表示修复 Ti 将非崩溃行为与所有先前崩溃的输入 c ∈ bi 相关联,但其他存储桶 bj ∈ B \ bi .4 没有任何崩溃
Ideal Bucketing 的一个微妙之处是单个输入可能会触发多个 bug 的特殊情况。例如,同一执行路径上的两个单独的缓冲区溢出副本(即两个错误 b1 和 b2)可能会在一次执行中(两次)覆盖堆栈。根据我们的定义,相应的修复 T1 和 T2 都不会对崩溃的输入进行存储。但是,我们可以扩展定义以考虑转换 T1 和 T2 的组合,以将此类崩溃输入放入表示复合故障的单独存储桶中。尽管在概念上很有用,但我们专注于逻辑离散的修复(基于开发人员补丁),以将崩溃的输入与错误相关联,以便通过实验比较真实和近似的修复是站得住脚的。在实践中,模糊测试器生成的输入通常会触发单个错误,我们的结果证实了这一观察结果。 对复合故障进行分类是一个悬而未决的问题 [22],我们将使用程序转换对此类故障进行分类的考虑留给未来的工作。
检测重复项
模糊测试分类的一个目标是近似于真实情况的理想分桶策略,从而最大限度地减少工程师使用模糊测试器识别缺陷的开销和混淆。近似值是通过唯一的调用堆栈哈希或唯一的分支序列等完成的。 但是,此类近似可能会失败,从而导致崩溃 inputs 的分桶错误。误桶可分为两类 [41]:
- 重复的 bug 报告和
- 隐藏的唯一错误:崩溃分桶(或“过度压缩”)遗漏的未报告的唯一错误。
在本文中,我们处理了第一种重复 bug 报告的情况。 现在,我们介绍如何根据修复转换 Ti 来检测重复的错误报告,其中 Ideal Bucketing 不成立。 考虑模糊测试程序生成的两个示例错误报告:错误 1 的崩溃存储桶 b1 = {c1} 包含崩溃的输入 c1,以及错误 2 的 b2 = {c2}。如果 c2 真的由于 bug 1 导致程序崩溃,我们说 b2 是一个重复的 bug 报告。也就是说,正确的分桶意味着 b1 = {c1, c2},并且不应报告 bug 2。重复的 Misbucket 错误地暗示了 bug 的唯一性,从而增加了处理模糊测试程序输出的工程师的分类负担。

也就是说,一些 cup ∈ bj 实际上由 Ti 修复的被认为是属于 bj 的不同独特错误 j 的崩溃。根据我们对 Ti 的正确性假设,Ti 修复的任何崩溃都必须属于 bi 才能保持理想的桶。请注意,如果 c 是 bj 中唯一的崩溃,则暗示了一个唯一的桶,从而导致错误 i 作为不应该存在的其他错误 j 的重复报告。
总之,给定正确的 Ti,我们可以确定 Ground Truth Ideal Bucketing,并将重复的错误报告检测为与 Ideal Bucketing 的偏差。
语义崩溃分桶过程
我们的公式导致了识别模糊测试器中错误分桶的简单过程。图 2 说明了该过程。Fuzzer 采用程序 P 和输入来生成一组崩溃 C = c1, . . . , cn .模糊测试程序根据其用于识别唯一 bug 的内置方法报告一组崩溃的输入。我们将模糊测试程序输出表示为一组不相交的唯一错误,由 I 索引:Bfuzzer = Ui ∈I bi
出于实用性考虑,默认情况下,模糊测试程序不会保留所有生成的崩溃输入。相反,模糊测试程序会丢弃它认为会触发它已经看到的 bug 的任何崩溃输入,并且通常会为它认为唯一的每个 bug/存储桶输出一个代表性崩溃。这表示为 Bfuzzer = (b1 = {c1}) ⊎ (b2 = {c2}) ⊎ · · ·⊎ (bn = {cn }).
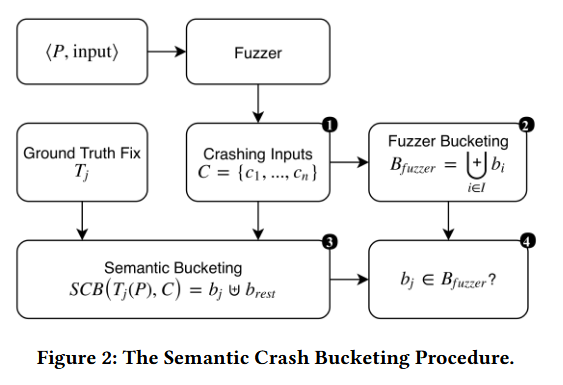
函数 SCB 将崩溃集 C 和地面实况修复 Tj 3 作为输入。对于单个修复 Tj ,SCB 通过在修改后的程序 Tj (P) 上运行每个崩溃 c ∈ C,将崩溃集 C 分区为不相交的集合 bj ⊎ br est。集合 bj 包含由 Tj 固定的所有输入,就像在 Ideal Bucketing 情况下一样,而 brest 包含仍然导致 Tj (P ) 崩溃的所有输入。最后一步 4 测试由 Tj 区分的非空存储桶 bj 中的崩溃是否包含在 Bfuzzer 中。 因为 Bfuzzer 包含一个唯一错误的分区,在任何 bi 中只有一个代表性的崩溃,所以测试 bj ∈ Bfuzzer 只有两个结果: (1) |bj |= 1 的 b0 中,等于 Bfuzzer 中的某个 bi,这意味着 Bfuzzer 精确地为错误 j 或(2) |bj |> 1 表示 c ∈ bj 中的崩溃在 Bfuzzer 中被划分为多个存储桶,这意味着 fuzzer 报告了重复的错误。为简单起见,图 2 说明了修复 C 中至少一个崩溃输入的单个修复 Tj 的过程。Ideal Bucketing 检查 C 中的每个崩溃输入是否可以由一个或多个修复 T 唯一修复(和分桶)。
生成近似修复
空指针
查找此类导致崩溃的变量(null)一般过程为:
- 将 GDB 附加到程序,在崩溃的输入上运行它。
- 提取崩溃时报告的源代码行和代码。
- 解析代码以获取指针取消引用语法(例如,p->q)。
- 逆向工作,提取被取消引用的程序变量(例如,从 p->q 中提取 p)。使用 GDB 测试变量在调试器环境中是否为 null。
- 如果变量为 null,则返回变量和关联的行号。如果不是,则向后移动一个基本块并从 (3) 继续。
如果该过程成功,我们将替换模板程序变量,并在 null 取消引用之前插入候选补丁。null 检查可能更早放置,并且 true 修复可能会间接禁止特定变量为 null(参见。 图 1a) 中的正确 SQLite 修复。我们的决定是一个廉价的妥协方案,我们证明它在实践中效果很好。
在使用 SCB 的补丁之前,我们首先验证修改后的程序是否不再因输入 c 而崩溃。补丁生成过程可以生成多个候选补丁,但我们的实现采用第一个崩溃修复补丁进行分桶。
栈溢出
我们的方法是截断可能导致无效访问的内存写入。故障忽略计算 [44] 和漏洞利用缓解 [33] 中的应用程序使用类似的机制。
1 | // modify a possible overflowing memcpy call |
我们重写现有调用,并将复制的数据长度限制为默认的具体值 1。将数据限制为仅一个字节近似于保守的天使值 [13],这可能会导致程序不崩溃。请注意,存在其他可能性:例如,我们可以检测代码以获取在运行时观察到的实际 angelic 值,并使用这些值来构建修复。我们的实验表明,我们当前的选择对于精确分桶效果很好。
与近似 null 修复相比,溢出修复不会尝试停止执行:如果我们不知道其边界,那么在潜在缓冲区的长度上放置条件将被证明是有问题的。 相反,在调用不安全函数之前简单地退出会过度拟合到唯一的崩溃输入,这些输入会在函数之后崩溃。 此外,虽然在执行 C 库函数期间会发生内存损坏,但程序只会在稍后的某个时间点崩溃:一旦堆中发生无效的内存访问或者与 null 取消引用相比,这些行为激发了不同的语义提示,并强调了可配置方法的重要性。对于缓冲区溢出,我们实施一个过程来发现可能存在问题的库调用并解决其位置。然后,如图 4 所示的补丁模板替换了该调用。步骤如下:
- 使用 ltrace 从崩溃的程序运行中获取库调用的跟踪。
- 逆向工作,解析我们为其提供修复模板的跟踪中库调用的源位置。
- 在该位置应用模板,然后在原始崩溃的输入上重新运行程序。
- 如果程序不再崩溃,则发出近似修复补丁 TD。否则,从步骤 (2) 继续。
与 null 取消引用类似,我们验证程序不再因步骤 3 中所做的任何更改而崩溃,并使用第一个崩溃修复补丁进行分桶。
扩展语义崩溃分桶。补丁模板和补丁规则嵌入在 Python 脚本中,易于更改。用户可以根据 bug 类型或特定于应用程序的 API 的语义属性,为补丁应用程序定义自己的补丁模板和语义提示。GDB 接口和 ltrace 输出在脚本框架中可用于自定义。可以集成其他分析工具(例如 valgrind),但这自然需要一些额外的工作。
实验设计
硬件
我们在具有 2 个 Xeon E5-2699 CPU 和 20GB RAM 的 Ubuntu 16.04 LTS 服务器上运行实验。Crash Corpus 生成和模糊测试活动都在单个 CPU 内核上运行。在验证近似修复是否阻止崩溃时,我们使用了四个内核进行重新编译
软件
和AFL-Fuzz、CERT-BFF、Honggfuzz进行了对比
相关工作
我们的方法通常与识别 bug 唯一性和对崩溃输入进行分桶的现有工作有关 [14, 17, 18, 41]。特别有趣的是,Chen et al. [14] 提出了一种机器学习方法,该方法对编译器模糊测试器输出的有趣测试用例进行排名,并使用修复补丁作为基本事实,将崩溃的输入映射到独特的错误。Semantic Crash Bucketing 借鉴了使用 Ground Truth 修复来精确识别独特错误的理念,通过自动近似修复获得与 Ground Truth 相似的精度。
Pham et al. [41] 最近的工作使用了一种聚类算法,该算法依赖于输入的语义特征作为路径的约束,特别适用于符号执行器。我们的方法还促进了 bug 的语义表征,但侧重于对 bug 本身的语义属性敏感,而不是根据路径约束来总结崩溃的输入。从广义上讲,当前的技术操作和分析程序输入或以其他方式检测程序,以获得程序的“只读”行为(例如输入覆盖率 [14]、输入约束 [41] 或崩溃调用堆栈 [37])以对崩溃进行分组。据我们所知,SCB 是第一种利用程序修改的技术,用于在没有 ground truth 修复的情况下对崩溃的输入进行精确分组。
天使调试 [13] 试图通过用值替换表达式来修改程序,这与我们对 C 库函数的近似修复在概念上相似。然而,我们的问题关注点不同:我们在存在重复或未报告的 bug 时寻求准确的崩溃桶,而 Angelic 调试寻求修复失败的测试用例,同时保留现有的通过的测试用例。
在程序修改方面,我们的工作与故障计算有关 [35, 44]。例如,我们基于规则的修复模板应用与 Long 等人 [35] 提出的想法有相似之处,他们修改程序,以便空取消引用不会导致其崩溃。但是,故障忽略计算的目标是使程序执行能够灵活应对 bug (如 null 取消引用或被零分除错误)的崩溃诱导影响。相比之下,SCB 试图通过选择性地应用程序转换来隔离独特的错误,而不是提供一种自动的 catch-all 技术来保持程序运行以实现弹性。语法补丁促进了 “patches as better bug reports” [47] 的好处,以便工程师可以分析影响崩溃桶的语义效果。Peng et al. [40] 表明,在模糊测试时应用程序转换可以增加程序覆盖率并揭示更多错误;虽然我们的方法侧重于准确的崩溃桶,但我们的技术补充了这个新的想法。
故障定位 [15, 25, 32, 43] 和自动程序修复 [30, 33, 49] 在识别 bug 并自动修复它们方面有着相似的高级目标。这项工作与我们的工作广泛互补,提供了有助于准确识别补丁放置故障位置以及针对不同错误类别的适当程序转换的技术。
结论
我们引入了语义崩溃分桶,这是一种使用轻量级程序转换执行崩溃分桶的方法。然后,我们开发了一种自动方法,将补丁模板应用于近似真实的开发人员修复程序,以执行崩溃分桶。我们的方法使用可配置的规则(每个 bug 类指定一次),这些规则根据崩溃行为实例化和应用补丁模板。 与粗略的重复数据删除方法不同,规则和模板对特定于错误的语义属性和崩溃行为很敏感。 我们开发了针对 null 取消引用和缓冲区溢出的近似修复。我们进行了一项地面实况研究,将 SCB 和近似修复与 (a) 真正的开发人员修复和 (b) 三种最先进的模糊测试器(AFL、BFF 和 Honggfuzz)的崩溃重复数据删除进行了比较。 我们的结果表明,近似修复与真正开发人员修复的崩溃分桶精度相比具有竞争力,并且比所有测试的模糊测试器配置执行的重复数据删除性能要好得多。






