阅读笔记:Automatic Solution Summarization for Crash Bugs
Automatic Solution Summarization for Crash Bugs
- 我们提出了一种新颖的方法,可以自动总结崩溃跟踪的解决方案;
摘要
软件崩溃的原因可以隐藏在源代码和开发环境中的任何位置。当遇到软件崩溃时,Q&A 网站上讨论的反复出现的错误可以为开发人员提供解决其崩溃问题的解决方案。但是,开发者很难在搜索引擎上准确搜索到相关内容,开发者不得不花费大量的人工精力才能从返回的结果中找到合适的解决方案。在本文中,我们提出了 CraSolver ,一种方法同时考虑了崩溃痕迹的结构信息和导致崩溃的错误知识,以自动总结崩溃痕迹的解决方案。给定一个崩溃轨迹,CraSolver通过将基于碰撞轨迹的结构信息的建议位置相关相似性与基于官方文档网站的知识的额外知识相似性相结合,从问答网站检索相关问题。在从 Q&A 网站获得这些问题的答案后,CraSolver 根据多因素评分机制总结了最终的解决方案。为了评估我们的方法,我们从 Stack Overflow 构建了两个 Java 和 Android 异常相关问题存储库,大小分别为 69478 和 33566 个问题。我们使用 50 个选定的 Java 崩溃跟踪和 50 个选定的 Android 崩溃跟踪的用户研究结果表明,我们的方法在相关性、有用性和多样性方面明显优于四个基线。该评估还确认了我们的崩溃跟踪方法中相关问题检索组件的有效性。
引言
软件崩溃是一个严重的软件缺陷问题,通常需要开发人员以高优先级解决它们。但是,随着软件系统复杂性的增加,软件崩溃的原因变得越来越复杂。幸运的是,许多 bug 会反复出现,并且发生在不同的项目中,但相似 [1]。以前的研究 [2] [3] 报告说,大约有 17-45% 的 bug 可以被认为是重复出现的。因此,Q&A 网站上已经讨论过的反复出现的错误,例如 Stack Overflow (SO),可能会帮助开发人员解决他们自己的软件崩溃。
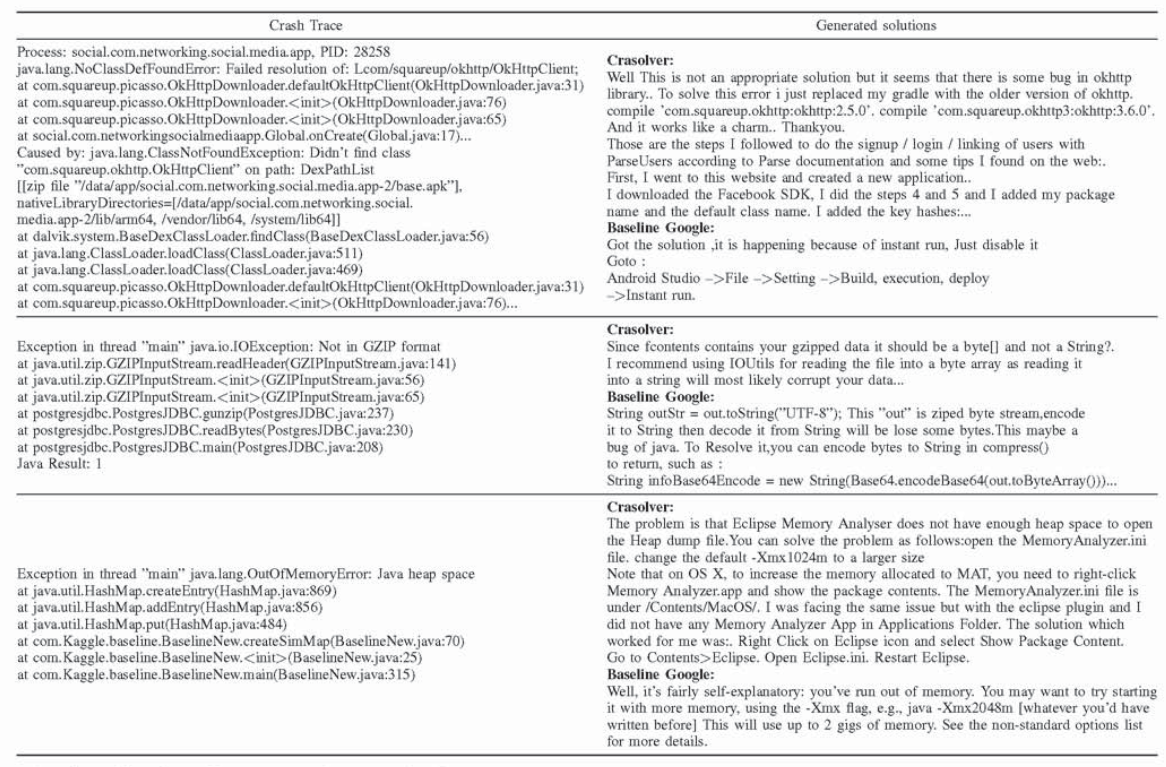
大多数主流编程语言都有自己的异常处理机制,该机制会生成崩溃跟踪,然后可以使用这些跟踪进行进一步调查。图 1 显示了此类崩溃跟踪的示例。我们将红色部分称为崩溃原因,将蓝色部分称为 stackframes。
通常,开发人员会将他们关于崩溃的问题组织到搜索引擎的查询中。但是,对于程序引发的大型故障跟踪,开发人员通常很难将此故障跟踪汇总到查询中。由于输入长度的限制,Google 和 Stack Overflow 等搜索引擎无法处理整个崩溃跟踪。通常,开发人员会尝试直接使用崩溃原因(如图 1 所示)作为搜索引擎输入,然后阅读返回的帖子以找到解决其软件崩溃的方法。但是,这种方法会错过很多堆栈帧中的重要信息,结果可能不够准确。更糟糕的是,返回的帖子中有很多嘈杂和冗余的信息,开发人员需要花费大量时间来消化并找到合适的解决方案。
同时考虑崩溃原因和堆栈帧以提供崩溃跟踪解决方案的自动化方法将帮助开发人员更有效地解决崩溃错误。最近,人们提出了两种自动生成编程问题解决方案的方法:AnswerBot [4] 和 CROKAGE [5]。AnswerBot [4] 为给定的技术问题生成一个以查询为中心的多答案帖子摘要。它旨在帮助开发人员在阅读文章的详细信息之前快速捕获与技术问题相关的多个答案帖子的关键点。CROKAGE [5] 采用编程任务的自然语言描述,并为该任务提供全面的解决方案。CROKAGE 建议同时包含代码和解释的编程解决方案。但是,这两种方法都不是为崩溃跟踪分析而设计的,并且需要编程问题的自然语言描述作为输入,这对开发人员来说很难。一些技术使用崩溃跟踪进行 bug 定位 [6]- [11]、自动程序修复 [1] [12] 和重复 bug 报告检测 [13]-[16](有关详细信息,请参见第 VI 节)。但是,据我们所知,尚未调查可指导开发人员修复导致给定崩溃跟踪的问题的自动生成的解释。
与问答任务 [17]-[19] 不同,崩溃跟踪可能与答案不共享任何词汇单位,并且它们传达的信息可能完全不同。为了解决这个问题,我们利用了这样一个事实,即一些讨论崩溃错误的问答帖子通常会附加一个崩溃跟踪,其中包含有关崩溃的某些信息。我们可以通过测量崩溃跟踪之间的相似性来检索相关问题。但是,许多现代程序依赖于通用包,因此不同的崩溃跟踪可能包含许多类似的令牌。如果程序依赖于某些常见软件包,则两个不同的崩溃错误可能会在其崩溃跟踪的不同位置共享许多相同的令牌。因此,传统的信息检索方法,即BM25 [20]、基于TF-IDF的信息检索[21]、基于词嵌入的信息检索[22]和基于文档到向量的信息检索[23],会带来偏差,效果不佳。崩溃原因和堆栈帧的结构信息可能是提高我们检索能力的关键点。此外,问答网站上的一些崩溃跟踪可能不完整,因为提问者只粘贴了崩溃原因并简要描述了崩溃。仅使用崩溃跟踪将无法检索所有相关的 Q&A 帖子。如果我们能引入一些关于要检索的崩溃 bug 的额外知识,这将大大改进我们的方法。遗憾的是,开发人员很容易了解崩溃跟踪的概念,但对于程序来说却很难。
为了解决这些问题,我们建议使用 CraSolver(Crash Solver),它将崩溃跟踪作为输入,然后返回 bug 的解决方案摘要。我们的方法同时考虑了崩溃跟踪的结构信息和崩溃错误的知识。首先,我们从 Stack Overflow 上的问题正文中提取所有崩溃跟踪,并使用 BM25 [20] 根据每个崩溃跟踪的崩溃原因部分检索一组相关问题。然后,我们提出了两个指标来评估给定崩溃跟踪与问题集中所有帖子之间的模拟性:(i) 基于给定崩溃跟踪和问题崩溃跟踪之间的堆栈帧的建议位置相关相似性;(ii) 额外的知识相似性度量,即来自崩溃原因的官方文档的知识与问题标题之间的相似性。将返回排序的前 k 个问题列表和属于这些问题的答案。然后,我们根据几种特征对这些答案段落进行评分,并借鉴最大边际相关性算法 [24] 的思想来生成解决方案摘要。最后,我们过滤掉一些低质量的句子并输出解决方案。
我们为 Stack Overflow 中的 Java 问题和 Android 问题构建了两个存储库,其中问题正文中存在崩溃跟踪,大小分别为 69478 和 33566。我们随机选择了另外 50 个 Java 问题和 50 个 Android 问题,并提取了这些问题帖子中的所有崩溃痕迹。我们选择了四种方法作为我们的基线 - Google Search Engine、SO Search Engine、AnswerBot [4] 和 CROKAGE [5]。我们的实验表明,Cr a So l v e r 在相关性、有用性和多样性方面明显优于所有基线。我们方法中对检索组件的评估表明,在 Q&A 网站上搜索给定崩溃跟踪的相关问题的能力很强。
- 我们提出了一种新颖的方法,可以自动总结崩溃跟踪的解决方案;
- 我们引入了两个相似性指标来检索与崩溃跟踪相关的 relevant 问题,位置依赖相似性和额外知识相似性;
- 我们进行了广泛的实验来评估 CraSolver,证明了它与最先进的方法相比的有效性。
建议的方法
我们提出了一种新方法 Cr a So l v e r ,为程序引发的给定崩溃跟踪生成潜在的解决方案摘要。其框架如图 2 所示。Cr a So l v e r 将崩溃跟踪作为输入,并生成崩溃跟踪的解决方案摘要。其预处理和准备阶段、相关问题检索阶段和解决方案生成阶段的详细信息如下所述。
预处理和准备
为了在 Stack Overflow 上查找具有崩溃跟踪的问题,我们首先在 Stack Overflow 上手动检查了大量与异常相关的问题。我们观察到,大多数崩溃跟踪都使用 HTML 标记 (code) 或 (blockquote) 突出显示,并包含字符串 ‘’Caused by’ 或 ‘’Ex ception in“ 。因此,我们使用 Beautiful Soup [25] 和正则表达式来离线提取所有基于这些启发式方法的具有崩溃跟踪的问题。为了支持相关的问题检索阶段和解决方案生成阶段,我们准备了以下材料:
Crash Trace Index:我们使用 NLTK 包 [26] 对从 SO 问题中提取的所有崩溃跟踪进行标记。收集所有问题 ID 和崩溃跟踪对以构建文档语料库。然后,使用 Whoosh [27] 利用预处理后的文档语料库构建索引,类似于 Lucene [28],但用 Python 实现。Cr a So l v e r 利用此索引来初步过滤掉相关的问题集。
Exception Dictionary:为了确定崩溃跟踪的概念,我们将官方文档中的知识引入到我们的方法中。我们构建了一个字典,用于存储从官方文档站点抓取的所有异常的名称和相应的描述。
语言模型:为了衡量 SO 帖子与官方文档中的异常描述之间的相似性,我们构建了特定于领域的语言模型。我们收集 Stack Overflow 帖子的所有标题和正文文本,并使用空格和标点符号对提取的内容进行标记。我们使用 NLTK 包删除停用词并将每个单词词干化为语料库中的词根形式 [26]。然后,我们训练一个单词嵌入模型 FastText [29],将语料库中的每个单词表示为固定长度的向量。我们还计算词汇表中每个单词的 IDF 指标(逆向文档频率)。IDF 指标表示单词可能携带重要语义信息的可能性。我们使用 IDF 加权的单词嵌入向量作为语料库中每个单词的表示。通过这种方式,能够在问题检索阶段和解决方案生成阶段计算语义相似性。
相关问题检索
给定一个崩溃跟踪 CT,Cr a So l v e r 首先使用正则表达式来提取崩溃原因和堆栈帧。Cr a So l v e r 还会检查跟踪崩溃原因中包含的每个令牌。如果令牌与异常字典中的任何异常名称完全匹配(请参阅第 II-A 节),则添加相应的描述和异常名称作为崩溃跟踪的额外知识。
为了大大缩小搜索空间,Cr a So l v e r 使用 Crash Trace Index 来检索相关的问题集。Cr a So l v e r 通过 NLTK [26] 对提取的崩溃原因进行标记,并加载崩溃跟踪索引。Cr a So l v e r 使用 BM25 [20] 来测量索引中每个崩溃跟踪的词法相似性。来自预加载索引的崩溃原因和崩溃跟踪分别表示为 CR 和 P。相似性分数的计算方式如下:
在本文中,Cr a So l v e r 仅检索前 50 个相似问题,以避免在后期引入过多的噪声。Cr a So l v e r 进一步筛选出问题正文中的崩溃跟踪与查询崩溃跟踪不共享异常名称的问题。
在根据崩溃原因获得相关问题集后,Cr a So l v e r 进一步利用堆栈帧中包含的结构信息和官方文档中的额外知识来获得更精确的结果:
1) 位置依赖相似性:我们根据 Dang 等人 [13] 的见解,在本节中介绍了我们提出的位置依赖相似性:
- 导致 bug 的帧最有可能发生在 a 调用堆栈的顶部附近;和
- 两个相似调用堆栈中两个匹配函数之间的对齐偏移量可能很小。
对于给定的崩溃跟踪,Cr a So l v e r 提取其所有调用堆栈和相应的堆栈帧。我们将调用堆栈在整个崩溃跟踪中的位置表示为 s,将每个函数(标记)到其所属调用堆栈顶部的距离表示为 d。因此,Cr a So l v e r 将崩溃跟踪中每个标记 wi 的位置信息记录为一组:
额外知识相似性:为了了解崩溃跟踪的内容,我们引入了来自官方文档的额外知识。给定崩溃跟踪和相关问题集,C r a So l v e r 将崩溃跟踪的官方文档和相关问题的标题中的相应描述转换为两个单词袋,分别表示为 D 和 T。与 Yang 等人 [22] 对文档中单词的词嵌入向量进行平均不同,C r a So l v e r 使用 IDF 加权的词嵌入向量来表示文档。
Cr a So l v e r 加载第 II-A 节中提到的准备好的语言模型,并计算额外的知识相似性.
解决方案生成
为了避免一些冗余信息并生成一个全面的解决方案,我们借用了 Maximal Marginal Relevance 算法 [24] 的一个想法来生成解决方案。给定前 10 个相关问题的答案,CRA SOLVER 使用答案段落的粒度来生成最终解决方案。我们首先根据四个特征对每个答案段落(表示为 A)进行评分:
- 该段落所属问题的相关分数,如第 II-B 节所述;
- 带有崩溃跟踪描述的语义相似性分数,由公式 6 计算;
- 对答案进行投票 - 我们将对段落来源的答案帖子的投票设置为投票分数;以及
- 是否接受答案。如果接受段落所属的答案,我们将分数设置为 2,否则为 1。
在这项工作中,C r a So l v e r 选择了 3 个相关的段落,以防止输出太长。自然语言段落中包含在 HTML 标记 {code) 中的短代码片段将保留在段落中。不超过 20 行的长代码片段将与答案段落一起提取。C r a So l v e r 会将相应的长代码片段(如果有)附加到解决方案的末尾。