
阅读笔记:DEEPVSA: Facilitating Value-set Analysis with Deep Learning for Postmortem Program Analysis
DEEPVSA: Facilitating Value-set Analysis with Deep Learning for Postmortem Program Analysis
- 为了解决内存别名问题
- 提出新的神经网络架构
- 写神经网络的
摘要
值集分析(VSA)是功能最强大的二进制分析工具之一,已被广泛应用于从验证软件属性(如变量范围分析)到识别软件漏洞(如缓冲区溢出检测)等多个领域。然而,在死后程序分析中使用它来促进数据流分析时,它在处理内存别名识别方面表现出能力不足。从技术上讲,这是由于 VSA 需要根据控制流的上下文来推断内存引用,但运行中程序的意外终止留下了不完整的控制流信息,使得内存别名分析毫无头绪。
为解决这一问题,我们提出了一种新的技术方法。在高层次上,这种方法首先采用指令嵌入层和双向序列-序列神经网络来学习与内存区域访问相关的机器码模式。然后,利用该网络推断出 VSA 无法识别的内存区域。由于对不同区域的内存引用自然表明了非别名关系,因此所提出的神经架构有助于 VSA 更好地进行别名分析。与以往利用深度学习完成其他二进制分析任务的研究不同,本研究提出的神经网络具有根本性的创新。我们没有简单地使用现成的神经网络,而是引入了一种新的神经网络架构,它可以捕捉指令之间和指令内部的数据依赖性。
在这项工作中,我们将深度神经架构实施为 DEEPVSA,这是一款神经网络辅助别名分析工具。为了证明该工具的实用性,我们用它来分析 Offensive Security Exploit Database 中归档的 40 个内存损坏漏洞对应的软件崩溃。我们的研究表明,DEEPVSA 在分析内存别名方面可以显著提高 VSA 的能力,从而增强安全分析人员找出软件崩溃根本原因的能力。此外,我们还证明∗Equal Contribution.我们提出的神经网络优于其他二进制分析任务中广泛采用的最先进的神经架构。最后但并非最不重要的一点是,我们证明 DEEPVSA 在执行别名分析时几乎没有误报。
引言
尽管开发人员尽了最大努力,但软件仍不可避免地存在缺陷,这些缺陷可能会被利用成为安全漏洞。现代操作系统集成了各种安全机制,以防止软件故障被利用 [18, 36, 51, 53]。因此,要绕过这些防御机制并劫持程序的执行,攻击者需要不断变异漏洞利用方法并进行多次尝试。在尝试过程中,漏洞利用程序会触发安全漏洞,使运行中的进程异常终止。
为了分析意外终止(即程序崩溃),从而找出根本原因,软件开发人员或安全分析人员需要执行逆向污点分析 [17、20、39],追踪坏值是如何传递到崩溃站点的,从而找出导致崩溃的语句。从技术上讲,如果能在崩溃终止时获得与崩溃相关的控制流和数据流,那么这一过程就能大大简化,甚至实现自动化。
最近,大量研究表明,可以通过硬件跟踪(如 [30, 55])以最少侵入的方式记录程序的执行。因此,软件开发人员可以很容易地恢复与程序崩溃有关的控制流。然而,仅从执行跟踪中恢复数据流仍然具有挑战性,尤其是在没有源代码的情况下。正如最近的研究[55]所讨论的那样,这主要是因为数据流构建高度依赖于内存别名分析能力[4, 5]。
在过去研究中提出的所有内存别名分析技术中,值集分析(VSA)是最有效、最高效的技术,已被广泛采用,以提高在二进制级别识别内存别名的能力[6]。然而,在死后程序分析中,它在处理内存别名识别方面表现出能力不足。从技术上讲,这主要是因为 VSA 需要根据控制流的上下文来推断内存引用。然而,运行中程序的意外终止只会留下不完整的控制流信息,使内存别名分析变得毫无头绪。
为解决这一技术问题,我们引入了深度神经网络,以增强 VSA 在内存别名分析方面的能力,尤其是在软件故障诊断方面。更具体地说,我们使用该神经网络来学习每次内存访问所指向的内存区域。这种方法的原理如下。VSA 将进程的地址空间划分为几个非重叠区域(即堆栈、堆和全局),并将对不同区域的内存引用对视为非别名。由于与软件崩溃相关的控制流信息不完整,VSA 会丢失崩溃程序的执行上下文,在为不同内存区域分配内存引用时通常表现不佳。利用深度学习,我们可以学习与内存区域访问相关的复杂执行模式,还原 VSA 因控制流不完整而无法推断的内存区域,最终增强别名分析在死后程序分析中的能力。
与之前利用深度学习解决其他二元分析问题的研究(如 [15, 48, 49, 56])不同,本研究中使用的深度神经网络是新颖的。我们不是简单地将现成的神经架构应用到我们的问题领域,而是提出了一种新的神经网络架构。具体来说,我们提出的解决方案首先利用指令嵌入网络来捕捉每条指令的语义。然后,它采用双向序列-序列神经架构来学习指令之间的依赖关系,并预测每条指令的内存访问。通过这种新的设计方法,我们可以捕捉到指令内部和指令之间的依赖关系,从而准确预测每条指令试图访问的内存区域。正如我们将在第 3 节和第 4 节中讨论和演示的那样,这完美地反映了二进制代码分析的特点,并在软件故障诊断的背景下大大有利于别名分析。
我们将提出的技术作为 DEEPVSA 1 付诸实施,这是一款用于死后程序分析的神经网络辅助别名分析工具。据我们所知,DEEPVSA 是第一个在死后程序分析中利用深度学习改进别名分析的工具。我们手动分析了从进攻性安全漏洞数据库存档[47]中收集的 40 个内存损坏漏洞对应的程序崩溃,并将我们的手动分析与 DEEPVSA 的分析进行了比较。
我们发现,DEEPVSA 可以准确解决 VSA 在对崩溃执行进行分析时无法识别的约 35% 的未知内存关系。此外,我们还发现,别名分析的升级大大提高了追踪软件崩溃根源的能力。对于约 75% 的故障案例,DEEPVSA 能够协助后向污点分析找出其崩溃的根本原因。与其他二进制分析任务中广泛采用的神经网络相比,我们还证明了我们的新神经网络架构在内存别名识别中不会产生误报。
本文的其余部分安排如下。第 2 节概述了值集分析及其在死后程序分析中的局限性。第 3 节介绍了我们为改进别名分析而提出的深度神经网络。第 4 节介绍了我们的实施和评估,展示了 DEEPVSA 的实用性。第 5 节概述了相关工作。最后,我们在第 6 节中结束这项工作。
贡献
- 我们发现,深度神经网络是解决软件故障诊断中别名分析问题的一种可行方法。
- 我们提出了一种新的神经网络架构,可用于改进 VSA 的别名分析,从而提高诊断软件崩溃根本原因的能力。
- 我们将深度学习技术作为 DEEPVSAa 工具来实施,以促进别名分析,并通过使用 40 个不同的软件崩溃(总计约 160 万行执行跟踪)来证明其有效性。
背景和问题范围
正如最近的许多研究成果(如 [19, 55])所描述和讨论的那样,新的硬件组件可以以侵入性最小的方式跟踪程序的执行。有了这种功能,安全分析人员就能轻松获取与软件崩溃有关的控制流。然而,利用执行跟踪来确定崩溃的根本原因(即真正导致崩溃的指令)仍然具有挑战性。一方面,这是因为安全分析人员几乎无法访问崩溃程序的源代码。另一方面,这是因为安全分析师需要分析崩溃跟踪的数据流,这涉及二进制级别的内存别名分析。为了应对这一挑战,可以采用值集分析法(VSA)。在本节中,我们首先介绍如何使用软件仪器和硬件跟踪来记录程序的执行。其次,我们简要介绍如何对记录的执行跟踪进行值集分析。第三,我们将具体介绍如何使用导出的值集执行别名分析,从而诊断软件崩溃的根本原因。最后,我们将更深入地讨论 VSA 在许多实际应用中表现不佳的原因。
用于软件调试的程序跟踪
软件仪表技术涉及向代码中插入特定的指令或代码片段,以便在程序执行过程中收集各种信息或执行特定的任务
长期以来,软件仪表技术(它涉及向代码中插入特定的指令或代码片段,以便在程序执行过程中收集各种信息或执行特定的任务)一直被用于全面记录程序的执行情况,从而帮助诊断程序崩溃的根本原因(例如 [38, 37])。然而,这种方法会给软件的正常运行带来巨大的开销。为了尽量减少额外的开销,有人提出了一些轻量级仪器技术(如 [41, 40])。虽然这些技术在协助软件调试方面具有较低的侵入性和信息量,但这种轻量级方法不能用于完全恢复与软件崩溃有关的控制流。
最近,硬件辅助处理器追踪技术的发展大大改善了这种状况。随着英特尔 PT [27] 和 ARM ETM [2] 等全新硬件组件的出现,软件开发人员和安全分析人员几乎不需要任何开销就能跟踪执行的指令,并将其保存在循环缓冲区中。在程序崩溃时,操作系统会将这些跟踪信息纳入崩溃转储。由于这种崩溃后的人工制品同时包含崩溃内存的状态和执行历史(即崩溃前最后执行的 N 条指令),软件开发人员不仅可以检查崩溃时的程序状态,还能完全重建导致崩溃的控制流。
在这项工作中,我们将重点使用增强型值集分析技术来分析上述崩溃后人工制品,从而促进崩溃程序的根本原因诊断。值得注意的是,上述轻量级软件仪器方法不在本研究范围内,因为它们无法提供完整的指令跟踪,无法通过值集分析识别内存别名,从而找出崩溃的根本原因。
值集分析

值集分析是一种用于静态分析汇编代码或指令跟踪的算法。根据内存布局一般遵循的观察结果,VSA 将内存划分为 3 个互不相联的内存区域—全局堆栈和堆—并相应地将指令分配到这些区域。对于某些指令,VSA 通过研究指令的语义来实现区域分配。例如,从二进制代码的角度来看,对全局变量和堆栈变量的访问显示为 [absolute-address] 和 [esp-offset]。因此,VSA 可以很容易地将全局和堆栈区域分别与指令 mov edx,[0x8050684] 和 lea eax,[esp+4] 联系起来。对于其他指令,VSA 会执行简单的前向数据流分析,以保守的方式确定与指令绑定的区域。以图 1 所示的指令跟踪为例。第 4 行的指令表示写入目标内存 [eax]。通过前向数据流分析,VSA 可以轻松确定 eax 的值是通过第 3 行传递的,因为库函数 malloc 将其返回值放在寄存器 eax 中。鉴于 malloc 的语义是在堆上分配一个内存区域,然后将其引用返回给调用者函数,VSA 可以轻松地将堆区域分配给第 4 行的指令。
请注意,全局区域由初始化和未初始化数据段组成。所谓 “保守方式”,指的是如果数据流传播因未知内存引用而受阻,VSA 不会主动推断内存单元中的值。
除了以上述方式将指令分配到内存区域外,VSA 还会跟踪类似变量的实体,这些实体被称为 a-loc。按照惯例,a-loc 可以是寄存器、堆栈上的内存单元、堆上的内存单元或全局区域中的内存单元。以图 1 所示的指令跟踪为例。寄存器 a-loc 包含所有寄存器 esp、eax 和 ebp。全局 a-loc 包含 [0xC8]。堆 a-loc 包括 [esp]、[esp+0x8]、[esp+0xC] 和 [ebp+0x8]。堆 a-loc 包括 [eax] 和 [eax+0x4]。需要注意的是,如表 1b 所示,VSA 将非寄存器 a-loc 表示为内存单元所持值与指示该内存单元地址的值集的组合。例如,指令 mov [esp+0x8],eax 访问堆栈内存,VSA 将其对应的堆栈 a-loc 指定为 [esp+0x8] (⊥, [-0xC, -0xC], ⊥)。这里,[esp+0x8] 表示堆栈内存单元的名称,(⊥, [-0xC, -0xC], ⊥) 是内存地址的值集,或者换句话说,esp+0x8 在该指令位置可能等于的值。
对于识别出的每个 a-loc,VSA 会计算出一个值集,表示每个 a-loc 可能等于的值集。按照惯例,VSA 将这样的值集表示为与所划分的三个内存区域有关的 3 元组。对于元组中的每个元素,VSA 都指定了一个偏移量范围,表示 a-loc 相对于相应内存区域可能等于的值。
为了说明这一点,我们以寄存器 a-loc esp 为例。如表 1b 第一行所示,为简洁起见,VSA 将其值集指定为 3 元组(全局 →⊥,栈 → [-0x14,-0x14],堆 →⊥)(⊥,[-0x14,-0x14],⊥)。在这个集合中,⊥ 是表示偏移量空集(即 ∅)的符号。它反映了这样一个事实,即在 x86 架构中,寄存器 esp 是堆栈指针,不能指向堆或全局区域中的任何内存单元。由于第一条指令的语义是将寄存器 esp 从堆栈起点偏移 0x14,因此 VSA 为寄存器 a-loc esp 赋值 {-0x14},并将此值集附加到堆栈。需要注意的是,为了规范的一致性,我们将绑定到堆栈的值集 {-0x14} 写成 [-0x14,-0x14]。
别名分析和根本愿意诊断
别名分析
鉴于程序崩溃前执行的指令序列指定了控制流,VSA 可以跟踪 a-loc、推导值集,并通过检查与每个 a-loc 关联的值集执行内存别名分析。为了说明这一点,我们再次以图 1 中描述的指令跟踪为例,假设它们代表了程序崩溃前的整个执行跟踪。假设表 1b 显示了从指令跟踪中识别出的每个 a-loc 的值集,我们可以很容易地观察到第 6 行的 [esp] 和第 11 行的 [ebp+0x8] 指向同一个内存区域,换句话说,它们是彼此的别名。此外,我们还可以看到第 4、12 和 18 行的 [eax] 也互为别名。这只是因为与这些内存区域绑定的 a-locs 带有与其地址相对应的重叠值集,即 [esp] 和 [ebp+0x8] 为 (⊥, [-0x18, -0x18], ⊥); [eax] 为 (⊥, ⊥, [0,0]) 。为了更好地理解 VSA 对别名分析的影响,我们从表 1b 中指定的值集中推导出所有别名和非别名关系,并将其描述在表 1a 中所示矩阵的上三角部分。
根源诊断
有了别名分析结果和值集,就可以比较容易地进行反向污点分析,从而找出程序崩溃的根本原因。为了说明这一过程,我们继续以图 1 中的示例为例。鉴于程序在第 18 行执行间接调用时崩溃,我们可以很容易地发现,坏目标 [eax] 是通过第 12 行的指令传递的,在该指令中,内存 [eax] 被赋值为常数 0x1。 如上所述,第 12 行和第 18 行的 [eax] 互为别名。因此,我们可以有把握地断定,坏的目标地址最初来自第 12 行的指令 mov [eax],0x1。通过这样的逆向分析,我们可以将指令 mov [eax],0x1 视为崩溃的根本原因。
问题范围
如上述例子所述,VSA 在别名分析方面表现出完美的性能,我们可以成功找出崩溃的根本原因。然而,这并不意味着 VSA 可以显著解决内存别名问题,从而完美地促进死后程序分析。为了证明这一点,我们再次以图 1 所示的指令跟踪为例。不过,与上述设置不同的是,我们假定跟踪只能从第 6 行开始。如第 2.1 节所述,硬件跟踪组件将指令跟踪存储在一个大小有限的循环缓冲区中。因此,安全分析人员通常无法获得完整的崩溃跟踪,只能获得程序崩溃前的部分执行时序。在我们的示例中,通过截断跟踪,我们模拟了程序崩溃后人工制品中仅记录了最后 N 个指令的情况。
在表 1b 中,我们还显示了从该截断轨迹中识别出的 a-loc。与同图中从完整执行轨迹中得出的值集相比,我们不难发现,几乎所有与 a-locs 相关的值集都发生了变化。这是因为 VSA 在构建值集时进行了过度逼近,而缺失的上下文限制了 VSA 对内存区域或区域内偏移进行推理的能力。以 [eax+0x4] 所指示的 a-loc (T,T,T) 为例。在没有崩溃程序的完整执行上下文的情况下,VSA 会保守地假设 eax 可能等于任何值。因此,内存 [eax+0x4] 可以指任何内存区域,其任意偏移量由符号 T 表示。如第 13 行指令所示,[eax+0x4] 的值由全局区域的值分配。因此,与该 a-loc 绑定的值集可以表示为([0x2, 0x2],⊥,⊥)。根据从截断轨迹中识别出的 a-loc 及其值集,我们按照上述方法检查值集交叉,并在表 1a 所示矩阵的下三角部分说明别名和非别名关系。我们不难发现,在没有完整执行轨迹的情况下,VSA 会过度估计与 a-locs 绑定的值集,并保守地将许多内存对视为 mayalias 关系。由于 may-alias 表示不确定关系,表 1a 用问号”?利用这些结果来推导软件崩溃诊断的数据流,我们不难发现,安全分析人员几乎无法得出任何有用的结果,或者换句话说,无法准确找出程序崩溃的根本原因,原因很简单,因为 VSA 追踪内存别名的能力有限。
技术方法
为了解决上述问题,我们提出了一种由深度神经网络驱动的技术方法。在本节中,我们首先讨论为什么深度学习有可能促进 VSA,从而改进软件崩溃分析。其次,我们简要介绍了其他二进制分析任务中常用的神经网络架构。第三,我们讨论这些现有神经网络的局限性,然后具体说明如何设计一种新的神经架构来更好地解决我们的问题。最后,我们将详细介绍新的神经架构,并说明如何将其集成到传统的 VSA 中。
概述
回想一下,当崩溃跟踪不完整时,VSA 的别名分析能力不足,因此无法进行根本原因诊断。如上所述,这是因为缺失的上下文限制了 VSA 确定某些指令内存访问区域的能力。为了解决这个问题,我们利用深度神经网络来增强 VSA,使其能够推断出指令的内存区域。下面,我们将介绍这一想法背后的原理,并说明为什么它能为软件崩溃诊断带来益处。
我们idea背后的合理性。
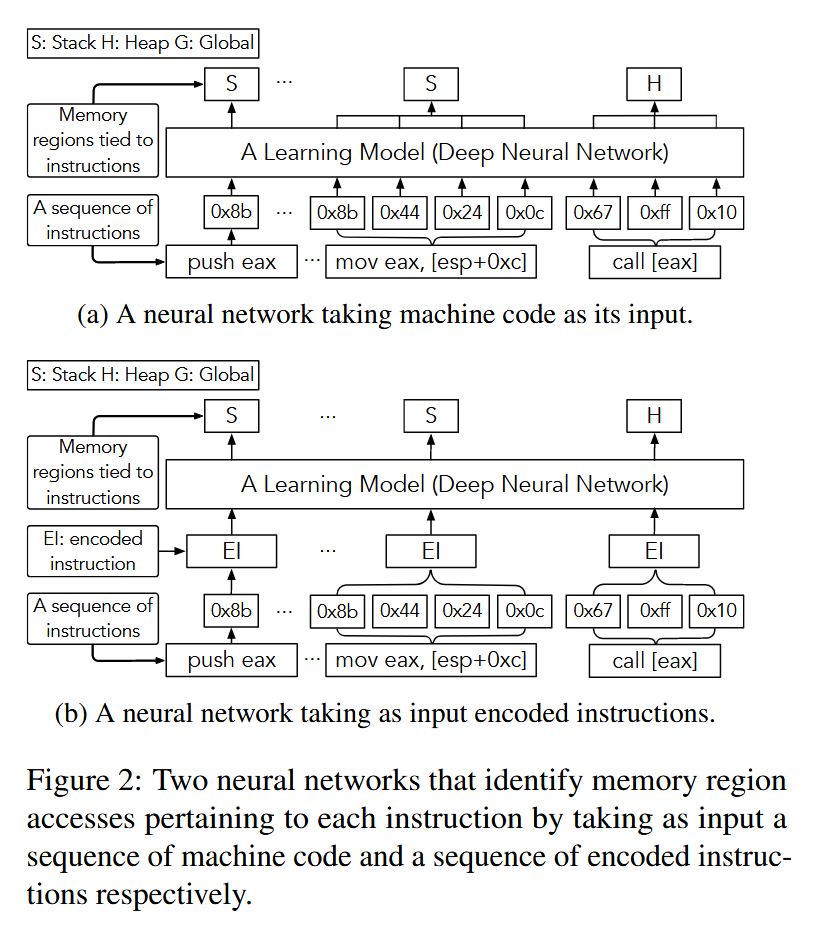
在以前的许多应用(如语音识别 [24] 和 API 生成 [25])中,已经证明某些序列到序列神经网络架构可用于从一连串输入中学习模式,从而有助于确定每个单独输入的标签。因此,为了增强传统 VSA 的能力,推断出每条指令所指向的内存区域,直觉告诉我们,可以将执行跟踪视为机器代码或指令的序列,将内存划分为不同的区域(如堆栈、堆和全局),将每个区域视为与每条指令相关的单个标签,并最终使用序列到序列深度神经网络来预测每条指令的标签。例如,给定以机器码 [0x68, 0x2f, 0x2f, 0x73, 0x68] 表示的推送 0x68732f2f 指令,我们可以使用图 2 所示两种设计中的任何一种来确定与该指令绑定的堆栈区域。如图所示,这两种设计的输入方式不同,一种是将机器码直接作为深度学习模型的输入,另一种是将编码指令作为模型的输入。在第 3.3 节中,我们将对这两种设计进行比较,并说明选择其中一种设计的原因。在第 4 节中,我们将展示它们的性能差异。
对根本原因诊断的影响。
有了上述增强功能,VSA 通常可以更好地进行别名分析,从而有利于软件崩溃的诊断。我们再次以图 1 所示的指令跟踪为例进行说明。回想一下,在没有完整执行上下文的情况下,传统的 VSA 无法确定 eax 所指向的内存区域。因此,它假定 [eax] 和 [eax+0x4] 可以代表任何内存区域,并为 eax 和 eax+0x4 赋值(T,T,T),最终导致崩溃的根本原因诊断失败。
根据与崩溃跟踪相关的指令序列,假设深度神经网络可以正确推断出第 6 行的寄存器 eax 指向堆中的内存区域。然后,VSA 可以给 eax 赋值集(⊥, ⊥, [X, X]),其中 [X, X] 表示堆上的未知地址。这样,VSA 就能进一步更新相应 a-loc 的值集。表 1b 中 “带 DL 的不完整跟踪 “一栏显示了更新后的值集。我们可以看到,第 12 行和第 18 行的内存引用 [eax] 互为别名,因为它们都引用了堆上的同一内存地址 [X,X]。有了这个别名分析结果,VSA 就能快速协助后向篡改跟踪第 12 行的指令—崩溃的根本原因—尽管这个崩溃跟踪是部分和不完整的。
已存在的神经网络
为了利用深度学习进行二进制分析,以往的研究通常使用三种类型的递归神经网络(RNN)—香草 RNN [33]、长短期记忆(LSTM)[22]和门控递归单元(GRU)[13]。在此,我们将依次对它们进行简要介绍。
香草递归神经网络
vanilla RNN(简称 RNN)专门用于处理一串值 x(1),. ., x(t)。当训练它根据过去的输入序列进行预测时,它通常会通过函数 g(t) 将序列映射到一个固定长度的向量 h(t):
从这个等式中我们可以看到,函数 g(t) 将过去的整个序列作为输入,并产生该序列的摘要 h(t)。在 RNN 中,h(t) 指的是隐藏状态。如图 3a 所示,RNN 可以展开为一个链式结构,其中每个隐藏状态都与前一个隐藏状态相连[23]。因此,g(t) 可以分解为函数 f 的重复应用,该函数控制着从上一个隐藏状态到下一个隐藏状态(即循环神经元)的转换。
要使用图 3a 中描述的链式结构进行预测,RNN 遵循前向传播,即从初始状态 h(0)开始,然后利用下面的更新方程计算相应的预测值 yˆ(t)。
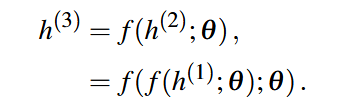
…..
长短期记忆
…
我们的神经网络架构
正如我们在第 3.1 节中所述,我们可以利用两种不同的设计机制来预测每条指令所指向的内存区域。对于图 2a 所示的设计,我们可以简单地利用上述任何一种递归神经网络,将机器码序列作为输入,学习隐藏在机器码序列背后的模式,并预测每条指令的内存区域。正如它们在其他二进制分析任务(如 [48, 15])中所展示的那样,我们可以预期这种设计在内存区域识别方面会有相当出色的表现。然而,根据下文所述的直觉,我们并没有采用这种设计。相反,我们使用图 2b 所示的替代设计来开发我们的技术。
以字节序列 [0x55, 0x89, 0xe5] 表示的指令序列 push ebp; mov ebp, esp 为例。现有的神经网络模型可以将这一机器码序列作为输入,并根据字节之间的依赖关系对相应的内存访问进行预测。不难发现,这种简单的方法忽略了这些指令的语义和上下文。正如第 2 节所述,在二进制分析中,指令的语义和上下文可以作为指标来推断与指令相关的内存访问。因此,直觉告诉我们,如果我们能构建一个神经网络,它不仅能捕捉字节之间的依赖关系,还能捕捉指令之间的依赖关系,那么它将对内存区域的识别大有裨益。
受此启发,我们选择了图 2b 中描述的设计,并构建了一个分层 LSTM 架构。我们在图 3b 中描述了这种学习模型的结构。我们可以看到,与用于其他二进制分析任务的现有神经网络类似,它首先通过字嵌入机制将每个字节映射为一个向量[9]。然后,它将每条指令的字节分组,并利用嵌入网络将每组字节转换为指令嵌入(即编码向量)。以指令嵌入作为输入,我们的神经架构进一步采用序列-序列网络[50]来预测与每条指令相关的内存区域。
与其他二进制分析任务普遍采用的上述现成递归架构相比,所提出的分层 LSTM 架构由两个网络组成。嵌入网络对一条指令中字节的相关性进行建模,而序列-序列网络则捕捉指令之间的依赖性。通过以这种方式设计模型结构,我们的神经网络模型能够在指令级别执行内存访问预测,并同时学习指令之间和指令内部的依赖关系。
然而,我们不难发现,这种新的循环架构并不能代表一种后向分析程序,即由连续指令决定与指令绑定的内存区域。但我们注意到,这种逆向分析是可行的。为了说明这一点,我们以下面的执行轨迹为例。
如上图所示,跟踪显示了调用 malloc 函数时执行的指令和相应的机器代码。在这里,高亮显示的指令和机器代码表示函数调用返回之前 [eax] 的最后一次定义。鉴于 malloc 调用将返回值放在寄存器 eax 中,表明该地址位于堆中,我们可以反向执行推理,得出结论:与高亮显示指令相关的内存访问位于堆区域内。
为了使我们的设计具有向前和向后推断记忆区域的能力,我们进一步将分层 LSTM 模型升级为双向链结构[46]。如图 3c 所示,我们的双向链结构同时应用于嵌入网络和序列到序列网络。在嵌入网络方面,我们的神经结构将一个从相应字节序列的起点开始向前移动的网络与另一个从相应字节序列的终点开始向后移动的网络相结合。关于序列到序列网络,我们的架构将一个前向嵌入网络的输出与一个后向嵌入网络的输出连接起来。然后,它将串联结果作为输入,并根据每条指令前后执行的指令序列对该指令进行内存访问预测。







