
分布式并行计算复习二
第六讲:MPI程序设计
数据分配方式:交叉分配/循环分配
假设有p个进程,每个进程得到每一个分配的第p个工作。
Example:有5个进程和12个任务
| P0 | P1 | P2 | P3 | P4 |
|---|---|---|---|---|
| 0,5,10 | 1,6,11 | 2,7 | 3,8 | 4,9 |
头文件
1 |
|
通信
MPI_COMM_WORLD: 默认的通信域;包括所有进程
确定进程数量
1 | MPI_Comm_size(MPI_COMM_WORLD,&p); |
第一个参数是通信域;第二个参数返回进程数。
1 | MPI_Comm_rank(MPI_COMM_WORLD,&id); |
第一个参数是通信域,第二个参数返回的是处理优先级(0,1,…..,p-1)
MPI结束调用
1 | MPI_Finalize(); |
在所有其他MPI库调用之后调用,允许系统释放MPI资源
编译程序
1 | mpicc -o foo foo.c |
运行程序
1 | mpirun -np <p> <exec> <arg1> ...; |
1 | MPI_Reduce(&count,&global_count,1,MPI_INT,MPI_SUM,0,MPI_COMM_WORLD); |
Wall-clock时间VS CPU时间
CPU时间
是指CPU用于处理指令的时间,是用户时间+系统时间
Wall-clock time(or wall time)
从一个任务开始到完成的时间流逝
CPU时间,IO时间,以及通信通道的延迟。
第七讲-素数筛选
埃拉托斯特尼筛法
- 创建无标记的自然数列表 2,3,4,…. n
- k<-2
- 重复进行
- 标记k^2到n之间的k的所有倍数
- 将最小的未标记的且大于k的数赋值给k,直到k^2>n
- 未标记的数就是素数
数据分配方式-块分配
- 平衡负载
- 容易标记倍数
- 如果n不是p的倍数,要确定所有者就比较复杂了
当n不是p的倍数,想要平衡工作负载,每个进程得到 n/p 向上取整 or 向下取整 n/p 个元素
method 1
r= n mod p
前r个块大小是 n/p 向上取整, 剩下p-r个块的大小是 n/p 向下取整
进程i控制的第一个元素是
进程 i 控制的最后一个元素是
控制 j 的进程
method 2
进程i 控制的第一个元素
进程 i 控制的最后一个元素
控制元素j的过程
1 |
1 | int MPI_Bcast( |
预期的执行时间: 顺序执行时间 + 广播数量*广播时间
优化方法
删除偶数、每个进程找到自己的筛选素数、重新组织循环
第八讲-弗洛伊德算法
1 | for k in range(0,n): |
点对点通信
1 | int MPI_Send( |
MPI_Send 返回
函数阻断,直到消息缓冲区空闲;消息缓冲区空闲的时间是消息被复制到系统缓冲区,或消息被传送。典型情况下:消息被复制到系统缓冲区,传输重叠的计算。
死锁
等待一个永远不会成真的条件的过程。
容易写出死锁的发送、接受代码:
1. 两个进程:都是先收后发送
2. 发送标签和接收标签不一样
3. 进程向错误的目标进程发送消息。
MPI程序中的安全性
一个依赖MPI提供缓冲的程序被认为是不安全的。这样的程序对于一些输入集可能运行没有问题,但对于其他输入集可能会挂起或者崩溃。
MPI标准允许MPI_Send以两种不同的方式行事:
- 可以简单地将消息复制到MPI管理的缓冲区并返回
- 可以堵塞,直到对方MPI_Recv的匹配调用开始
许多MPI的实现都设置了一个阈值,在这个阈值上,系统会从缓冲区切换到堵塞区。
- 相对较小的消息将由MPI_Send来缓冲
- 较大的消息将导致其阻塞。
MPI_Ssend保证堵塞直到匹配接收开始。
点对点通信是在标签和通信器的基础上进行匹配
集体通信不使用标签,它们只根据通信者和它们被调用的顺序来匹配
MPI_Gatherv可以从不同进程收集大小不同的数据块
MPI_Scatterv 需要将一个进程中的数据分发到不同进程
MPI_Alltoall的具体操作是:将进程i的发送缓冲区中的第j块数据发送给进程j,进程j将接收到的来自进程i的数据块放在自身接收缓冲区的第i块位置。
第一讲:CUDA介绍
异构计算
CPU:面向低延迟设计的核心(负责串行计算)
- 强大的ALU:减少操作延迟
- 大容量缓存:将长延迟内存访问转换为短延迟缓存访问
- 精密控制单元:用来减少分支延迟的分支预测方法 / 用于减少数据延迟的数据转发方法
GPU:面向大吞吐量设计的核心(负责并行计算)
- 小容量缓存:提高内存吞吐量
- 简单的控制单元:没有分支预测 , 没有数据转发
- 节能的运算器:大量且高延迟,高度流水线化实现高吞吐量
- 大量线程块:线程逻辑,线程状态
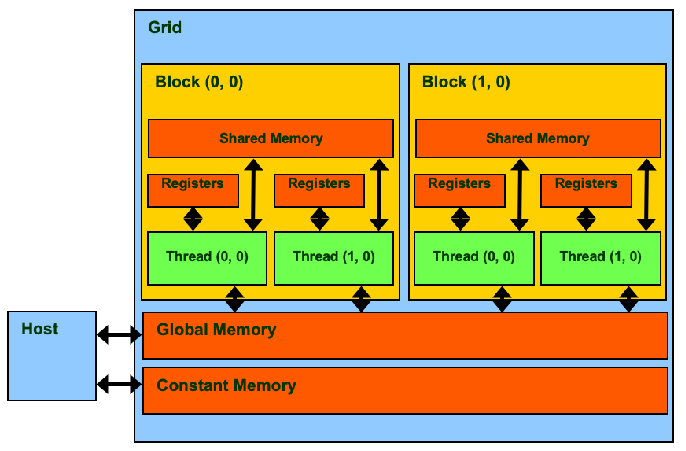
线程层次结构
线程:由CUDA运行时分发
线程束(Warp):一个最多32个线程的调度单元
线程块(Block):一个由用户定义的1到512个线程组。
线程网格(Grid):包含一个或多个线程块。为每个CUDA核函数创建一个网格。
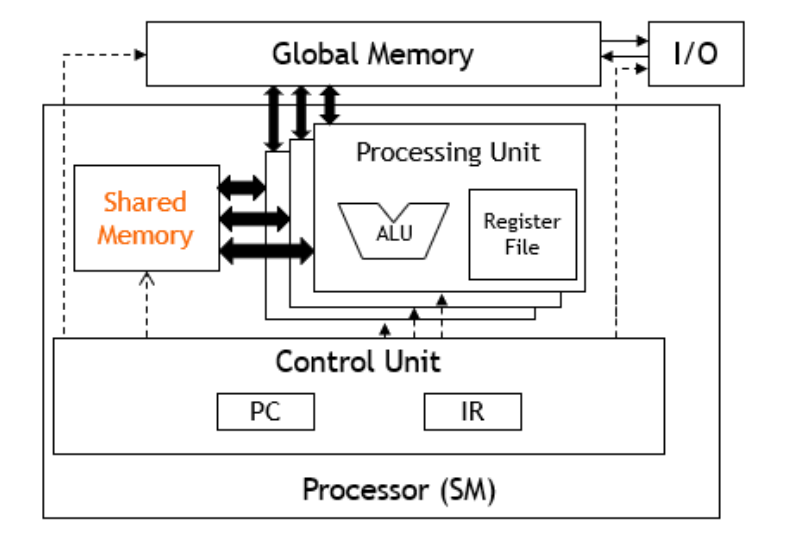
内存层次结构
寄存器:用于自动变量核寄存器溢出的每个线程内存。
共享内存:每个线程块的低延迟内存,允许块内数据共享和同步。线程可以通过这块内存安全地共享数据,并且可以通过 __syncthreads()进行屏障同步
全局内存:可以在线程块或线程网格之间共享的设备级内存
第二讲-CUDA并行化模型
threadIdx、blockIdx、blockDim、gridDim四个内建变量标识线程、线程块的位置和大小。
1 | Row=blockIdx.y * blockDim.y + threadIdx.y; |
线程调度
相对于其他线程块,每个线程块能以任何顺序执行;硬件可以随时自由地将线程块分配给任何处理器(内核可扩展为任意数量的并行处理器)。
线程束(Warp)作为调度单元,每个线程块都被分为多个包含32线程的线程束(Warp)执行。
线程束中的线程在SIMD中执行,N条执行路径就只有 1/N吞吐量了(应该避免在同一线程束内出现分支)。
硬件视图
第三讲-内存和数据
矩阵乘法
CGMA(计算/通信比):每次访问CUDA内核区域内的全局内存时执行的浮点计算次数。
CGMA越大,表示在GPU上的性能越好。
声明共享内存变量
1 | __shared__ float ds_in[N]; |
每个SM中有一个共享内存,有更高的访问速度,生命周期(线程块),通过load/store命令访问共享内存。
分块矩阵乘法
分块:将全局内存内容划分为多个分片,在每个时间点将线程的计算集中在一个或少量的分片上。
同步:
- 将分片内容从全局内存加载到共享内存
- 使用同步确保所有线程都准备好了开始阶段
- 让多个线程从共享内存中访问它们的数据
- 使用同步确保所有线程都完成了当前阶段
- 移到下一个分片
分块矩阵乘法内核
在分块操作代码中,每个线程加载矩阵M的一个元素和矩阵N的一个元素
处理分块中的边界条件
宽度为16的线程块包含了 1616=256个线程。在每个阶段,每个线程块从全局内存中进行了2 256=512次浮点载入,用于 256 (2 16)=8192次乘法/加法运算。(加法一次,乘法一次)
任意矩阵维度的分块内核
当一个线程要加载任何输入元素时,测试它是否在有效的索引范围内。不在写入0。
第四讲-性能考虑
当线程束中的线程通过判断分支执行不同的代码流路径时,就会发生控制分支现象。
采用不同路径的线程的执行在当前GPU中被串行化。
检查边界条件:
1 | if(Row<Width && p* TILE_WIDTH + tx<Width){ |
载入矩阵M分片时的两类线程块:
- 直到最后一个阶段,其分片都在有效范围内的线程块。
- 其分片部分在有效范围之外的线程块。



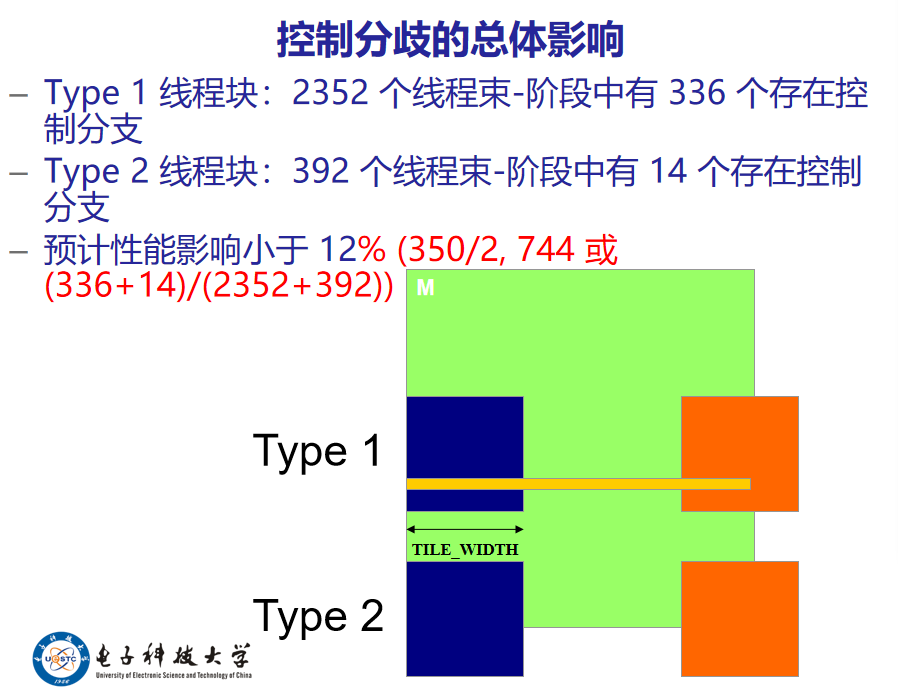
100-16*6=100-96=4
4 16=32 2 所以有2个线程块处于有效范围内
并行规约
一个有效的串行规约算法 O(N),遍历输入并在结果值和当前输入值之间进行规约运算。
并行规约树算法:
N个输入值,规约树执行N-1个操作
平均并行度为 (N-1)/ log(N)
使用共享内存,进行in-place规约,有n个元素,需要有log(N)步,需要 n/2个线程
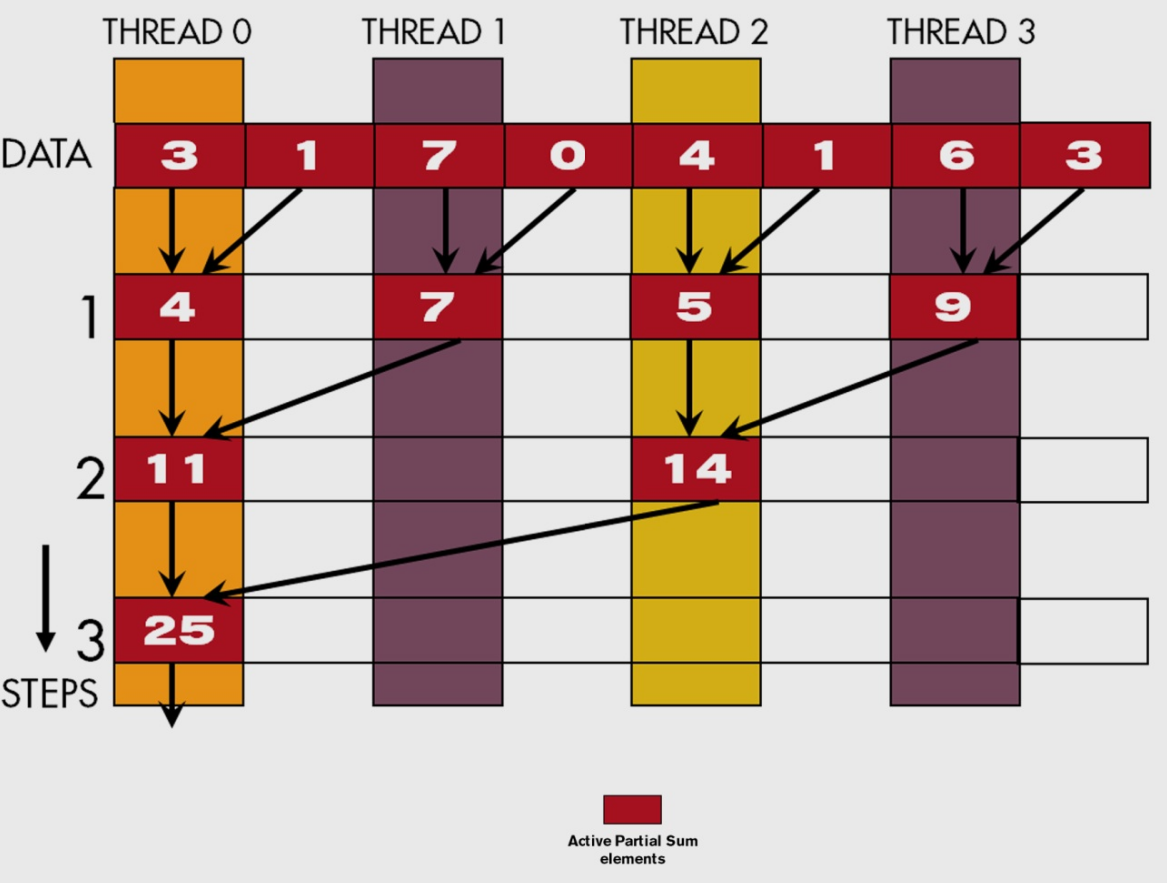
1 | for(unsigned int stride=1;stride<=blockDim.x ;stride*=2){ |
需要 __syncthreads() 以确保在进行下一步之前已经生成了每个版本的部分求和的所有元素
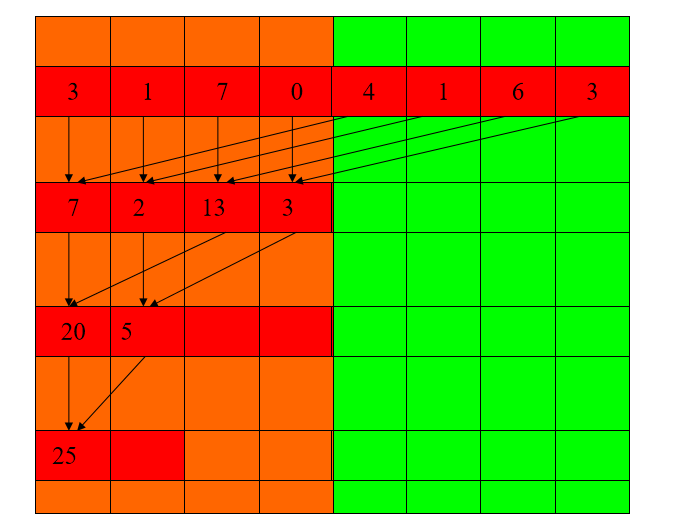
1 | for(unsigned int stride=blockDim.x;stride>0 ;stride/=2){ |
第五讲-并行计算算法
分段分区(Sectioned Partitioning)导致内存访问效率低下
- 相邻线程不访问相邻内存位置
- 访问未被合并
- DRAM带宽利用率差
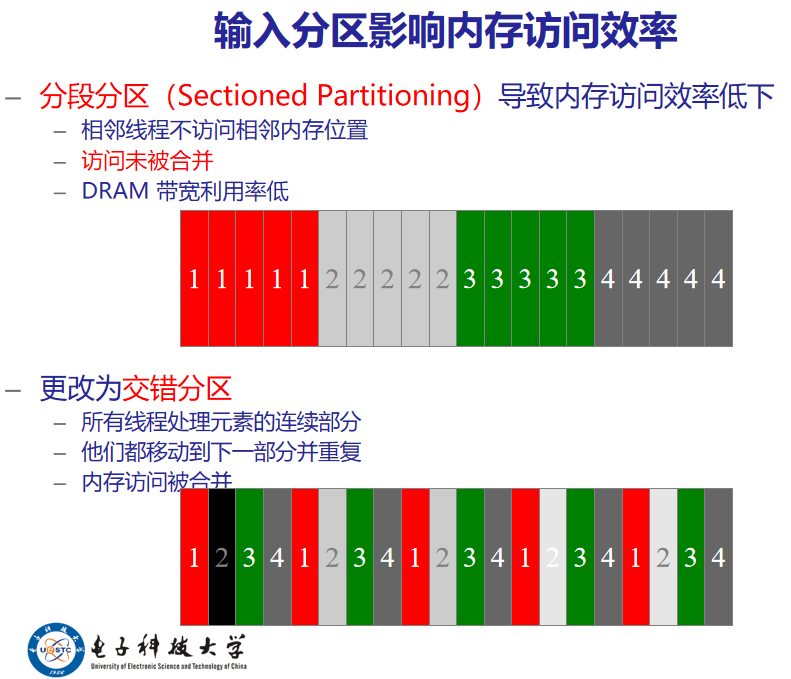
数据竞态条件
执行读取-修改-写入操作时可能发生数据争用
硬件确保在当前原子操作完成之前,没有其他线程可以在同一位置执行另一个读取-修改-写入操作。所有线程串行执行针对同一位置的原子操作。
1 | int atomicAdd(int* address,int val); |
私有化直方图内核
DRAM上的原子操作:每个读取-修改-写入操作都有两个完整的内存访问延迟。对同一变量的所有原子操作都被串行化了。
硬件改进:
共享内存上的原子操作:非常短延迟,每个线程块私有,需要程序员算法
Fermi L2缓存上的原子操作:中等延迟(1/10 DRAM),所有线程块之间共享
私有化是一种用于并行化应用程序的强大且常用的技术,适合于共享内存
一些数据集在局部区域具有大量相同的数据值,一个简单而有效的优化方法是每个线程在更新直方图的相同元素时将连续更新聚合为单个更新
第六讲-扫描算法
扫描操作接受一个二元关联运算符和一个包含 n 个元素的数组并返回数组。(前缀和类似)
低效扫描算法:
1 | __global__ void work_inefficient_scan_kernel(float *X, float *Y, int InputSize) { |




