
分布式并行计算复习一
第一讲
任务并行:将解决问题所需的不同任务分配给不同的核心。
数据并行:将用于解决问题的数据分配给不同的核心;每个核心对其数据的部分执行类似的操作。
通信 (Communication):一个或多个核心将它们当前的部分总和发送给另一个核心
负载均衡(Load Balancing) :均匀地分配工作给各个核心,以避免其中一个核心过于繁重
同步 (Sychroniaztion):由于每个核心以自己的节奏工作,需要确保核心不会超前于其他核心
第二讲-并行体系结构
并行硬件
Flynn’s Classification
- SISD:单指令流,单数据流
- SIMD:单指令流,多数据流
- 将同一指令应用于多个数据项
- 多个处理器同步执行同一程序(经典SIMD中,每个ALU等待下一条指令广播,然后操作;每个ALU执行相同指令或处于空闲状态)。
- 划分数据来实现并行性。每个处理器看到的数据可能不同。
- MISD:多指令流,单数据流
- MIMD:多指令流,多数据流
共享内存系统
一组处理器通过互连网络与存储系统相连;处理器可以直接访问系统中的所有数据。
在具有多个多核处理器的共享内存系统中,互连可以将所有处理器直接连接到主内存(UMA),或者每个处理器可以直接连接到一个主内存块,而处理器可以通过处理器内置的特殊硬件访问彼此的主内存块(NUMA)
UMA
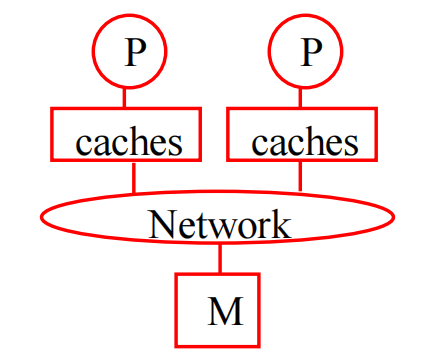
物理存储器被所有处理器均匀共享;
所有处理器访问任何存储字取相同的时间;
- 每台处理器可带私有高速缓存;
- 外围设备也可以一定形式共享
NUMA
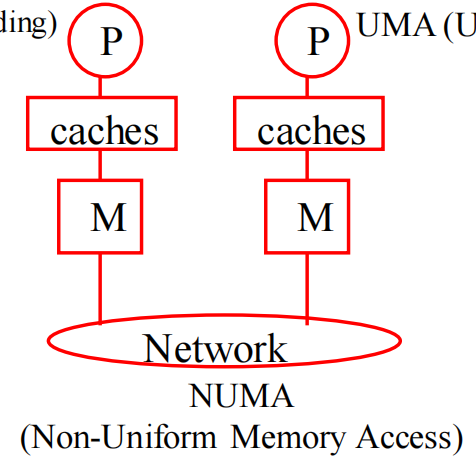
- 共享存储器分布在所有的处理器中;
- 处理器访问存储器的时间不均匀;
- 每台处理器照例可带私有高速缓存;
- 外设也可以某种形式共享。
分布内存系统
每个处理器都有自己的私有内存;处理器通过明确的消息传递或特殊函数共享数据
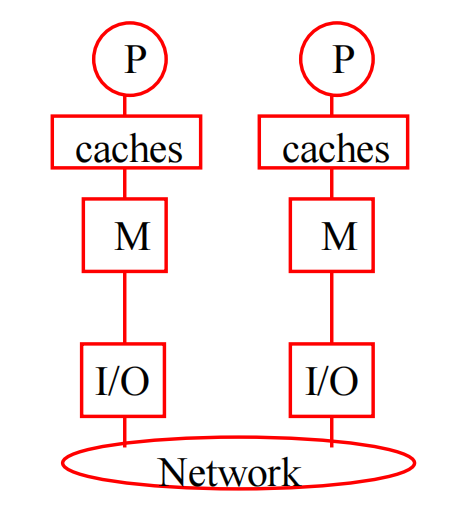
连接网络
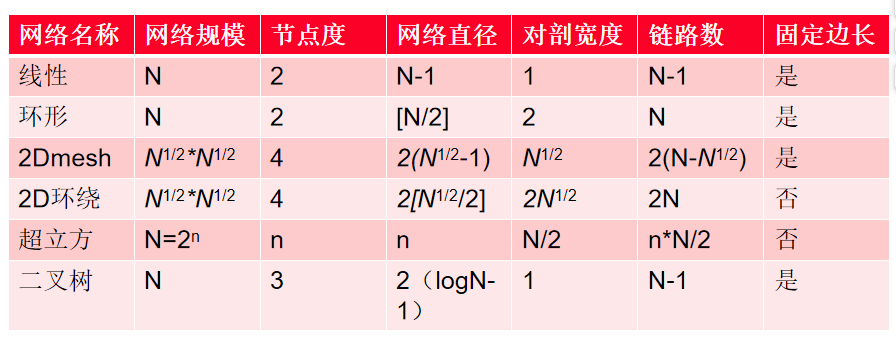
度量标准
节点度
每个节点的最大边数
如果边/节点的最大数量是一个与网络规模无关的常数,那是最好的,因为这可以使处理器组织更容易扩展到更多的节点数量。
网络直径
两个节点之间的最大距离;越短越好;任意点对之间通信复杂性的下限。
对分宽度
将网络大致分为两半的切割中的最小边数 - 决定了网络的最小带宽;K_n的分切宽度是O(n^2)
恒定边长
将节点和边布置在三维空间中,最大的边长是一个与网络大小无关的常数
连接网络
2D网格
只允许在相邻的交换机之间进行通信;节点排列成一个二维的格子或网格
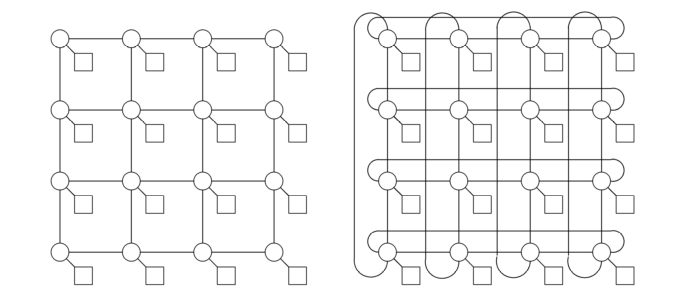
直径,对分宽带:O(n^0.5)
超立方网络
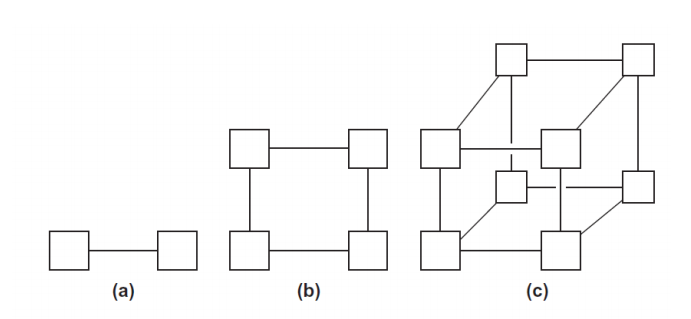
n=2^d Processors ,直接拓扑结构,节点的数量是2的幂,节点i与k个节点相连,这些节点的地址与i正好相差一个比特位置。Example: k=0111 和 1111,0011,0101,0110相连。
直径: d=logn,分割带宽 n/2 ,每个节点的边数:logn,恒定边长:No(最长边的长度随着n的增加而增加)
超立方网络路由
从 0010 向节点 0101发送信息:节点差3位,所以最短路径长度是3。
间接互联-蝶形网络
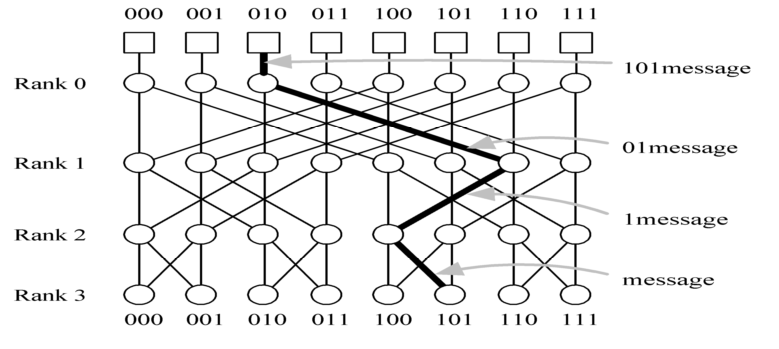
n=2^d个进程节点,由n(logn+1)个交换节点连接而成。
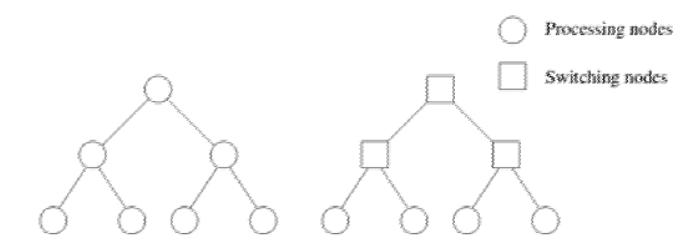
间接互联-树形网络
- 树状网络是指任何一对节点之间只有一条路径
- 静态树状网络在树的每个节点都有一个处理器
- 在动态树状网络中,中间层的节点是交换节点,叶子节点是处理器
More Definitions
时延:从源头开始传输数据到目的地开始接收第一个字节之间所经过的时间
带宽:目的地在开始接收第一个字节后接收数据的速率
缓存一致性
缓存一致性问题是指一个过时的值仍然存储在一个处理器的缓存中。当改变变量的值时:使所有副本失效(invalidate)或更新(update)。虚假共享,是指不同的处理器更新同一缓存线的不同部分的情况),CPU的缓存是在缓存线上操作的,而不是单个变量.
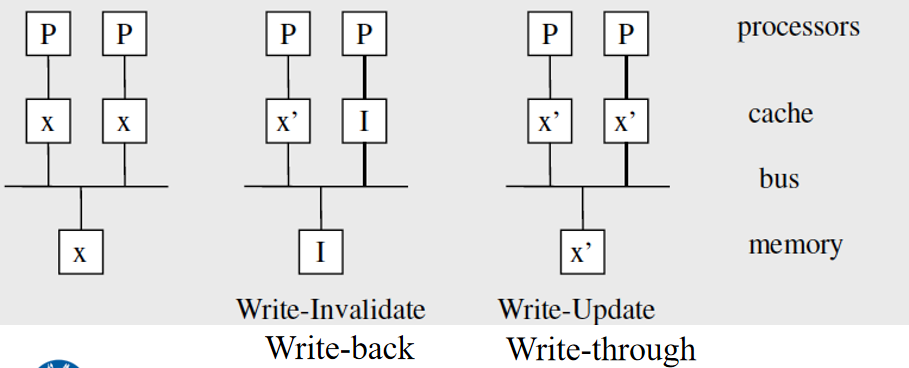
写直达( Write-through ):当该行被写入高速缓存时,会被写入主内存中
写回( Write-back ):数据不会立即写入。缓存中的更新数据被标记为脏,当缓存行被来自内存的新缓存行替换时,脏行被写入内存
写失效( Write Invalidate ):当处理器向其本地缓存写入时,其他缓存的副本必须被无效化.
- 如果是写直达,它也会更新内存中的副本
- 如果是写回,它使内存中的副本失效
写更新( Write Update ):当一个处理器写到它的本地缓存时,其他缓存的副本必须立即更新.
- 如果是写直达,它也会更新内存中的副本
- 如果是写回,数据并不立即写入。缓存中更新的数据被标记为脏,当缓存行被来自内存的新缓存行替换时,脏行被写入内存
典型状态MSI:共享、无效或修改( Shared, Invalid, or Modified )Shared:缓存中存在多个有效的副本;Invalid:数据副本无效;Modified:只存在一个有效副本。
基于监听的缓存一致性
核心共享一条总线,在总线上传输的任何信号都可以被连接到总线上的所有内核 “看到”,当内核0更新存储在其缓存中的x的副本时,它也在总线上广播这一信息,如果核1在 “监听 “总线,它就会看到x已经被更新了,它可以把它的x的副本标记为无效。缓存一致性的最常见的解决方案
- 一旦一个数据点被标记为脏:所有后续操作都可以在本地缓存中进行;不需要外部流量
- 过渡到所有缓存中的共享状态:所有后续的读取操作都变成了本地操作
- 如果多个处理器读取和更新相同的数据,就会出现一个基本的瓶颈:在总线上产生一致性请求;总线的BW限制: 对每秒的更新施加了限制
基于目录的缓存一致性
共享状态被保存在目录中,代表缓存块和它们被缓存的处理器的位图。网络的时延和带宽成为主要的性能瓶颈
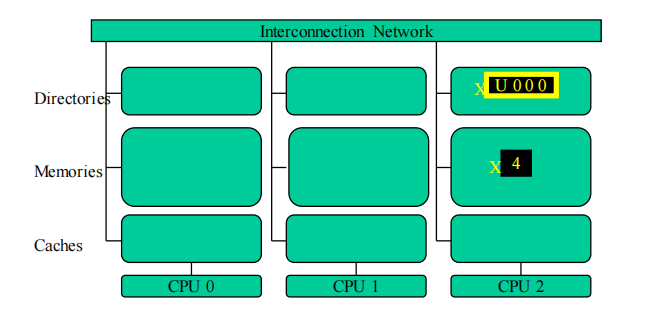
- Uncached—(U) :不在任何处理器的缓存中的块
- Shared – (用“S”表示):由一个或多个处理器缓存,只读
- Exclusive(用“E”表示):恰好由一个处理器缓存;处理器已经写入块中;内存中的拷贝已经过时
读了之后就变成S了,然后标记哪个有这个数据在cache中;写了就E,把其他的数据都无效,标记哪里独占这个数据
第四讲-并行程序设计方法
Foster方法
划分、通信、聚合和映射。划分和通信:处理与机器无关的问题,影响并发性和可伸缩性。聚合和映射:处理与机器相关的问题,影响局部性和其他性能问题。
划分
将要执行的计算和计算操作的数据划分成小任务。
域分解
将数据尽可能地划分为大小相等的小块。生成多个任务,每个任务都有一些数据和一组对数据的操作。先关注最大的数据结构或者访问最频繁的数据结构。
功能分解
关注需要执行的计算,而不是数据。这些任务的数据需求可能是不重叠的,也可能是有很大的重叠。通常通过流水线技术实现并发处理。
通信
确定在前一步骤中确定的任务之间需要进行哪些通信。划分产生的任务旨在并发执行,但不是独立执行。 执行任务A的计算需要任务B的数据。信息流在通信阶段中指定。 我们可以将两个任务之间通信的需求概念化为连接任务的通道
本地通信
任务需要从少量邻近的任务获取值 、创建展示数据流的通道。
全局通信
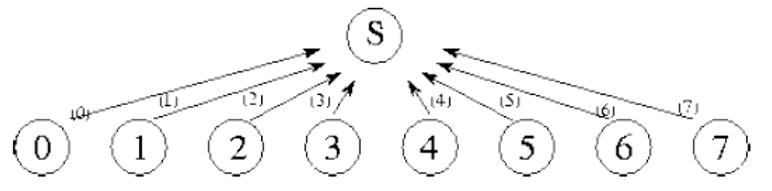
可能会导致过多的通信或限制并发执行的机会
分发通信和计算
分发N个数字的总和,每个任务i计算前i项和。将N个任务连接成一个数组,以便对分布在这些任务中的N个数字进行求和。每个通道都标有步骤编号以及在其上传达的值。
分治法
为了解决一个复杂的问题,将其划分为两个或更多大致相等大小的简单问题。递归应用此过程以产生一组不能进一步细分的子问题。当问题划分生成的子问题可以并发地解决时,分治法在并行计算中非常有效。
在logN步后,完整的总和在树的根节点得到。一种规则的通信结构,每个任务与一小组邻居进行通信。
类似于二叉树的结构。
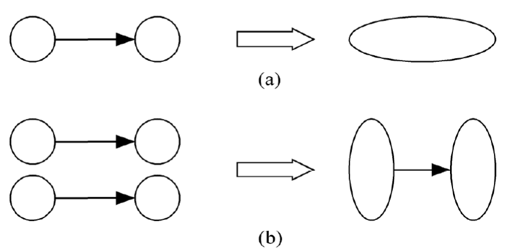
聚合
聚合或合并:将前两个步骤中的任务和通信组合成更大的任务。举例,如果必须在执行任务B之前执行任务A,则将它们聚合成单个复合任务可能是有意义的。在聚合过程中,需考虑是否值得合并,并确定是否值得复制数据/计算。
- 降低通信成本:将通过通道连接的任务组合在一起可以消除通信,增加并行算法的局部性。将发送和接收任务组合成组可以减少消息传输次数。
- 减少任务创建成本和任务调度成本。
映射
映射:将任务分配给处理器的过程。
开发映射算法的目标通常是最小化总执行时间。映射的矛盾目标:
- 最大化处理器利用率,即处理器的平均使用时间百分比
- 最小化处理器间通信(将通信进程映射到同一处理器)
为了最小化通信代价、并使每个进程/线程获得大致相同的工作量,映射是必需的。
More
设x是更新元素的时间,n是元素(间隔)的数量,m是迭代次数
串行执行时间: m(n-1)x
p是处理器数量,q是消息延迟
并行执行时间:
Reduciton(规约)
超立方体通讯时间
完全图通信时间:
Scatter 分发
第五讲—性能分析
加速比: Ts是串行执行时间,Tp是使用p个处理器的并行算法的运行时间。
效率: 是加速比除以p(处理器的数量)具有线性加速比的程序效率为100%。
Amdahl定律
f是计算中必须串行执行的操作比例,使用p个处理器执行计算所能达到的最大加速比。
程序95%的执行时间发生在一个可以并行执行的循环内。如果使用8个CPU执行程序的并行版本,期望的最大加速比为多少?
1/(0.05+(1-0.05)/8)=5.9
局限性
高估了可实现的加速比,忽略了通信时间
Gustafson-Barsis定律
一个运行在10个处理器上的应用程序在串行代码中花费了3%的时间。该应用程序的比例加速度是多少?
10+(1-10)(0.03)=10-0.27=9.73
如果一个程序要在8个处理器上达到7的比例加速度,那么并行程序在串行代码中可以花费的最大比例是多少?
7=8+(1-8)x x=0.14
Karp-Flatt Metric
(并行计算中固有的串行部分+ 处理器通信和同步开销)/(单处理器执行时间)
由于常数e是固定的,因此较大的串行部分是导致加速比较低的主要原因。
由于常数e不断增加,因此并行开销是导致加速比较低的主要原因
等效率指标
并行系统的可扩展性:衡量其随着处理器数量增加而提高性能的能力
等效率性:衡量可扩展性的一种方式





