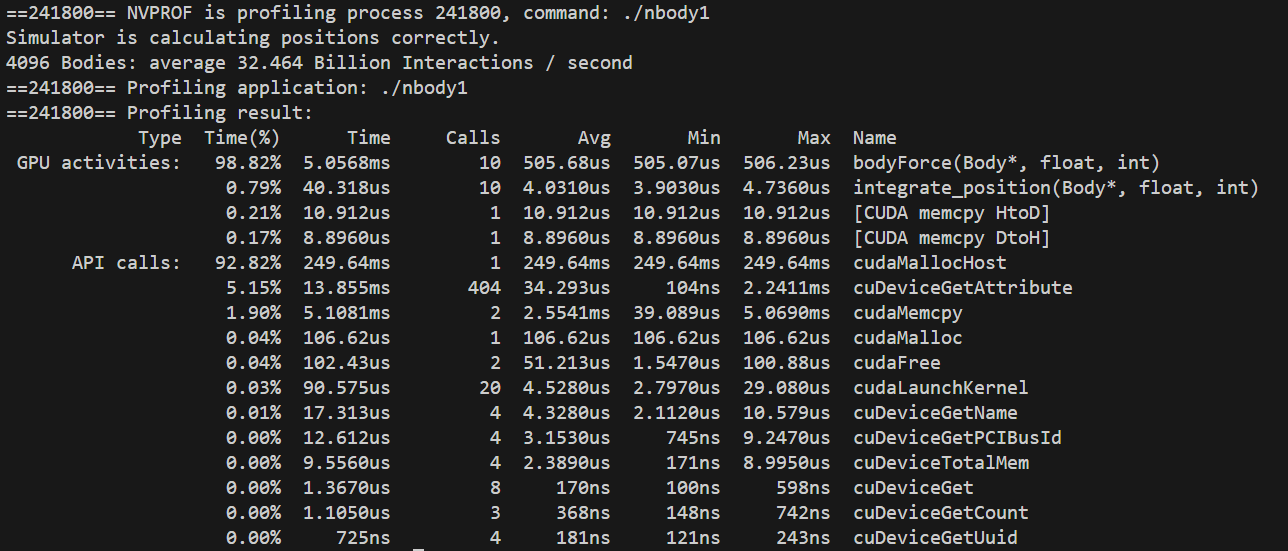
#include<math.h> #include<stdio.h> #include<stdlib.h> #include"timer.h" #include"check.h" #include<cuda_runtime.h> #define SOFTENING 1e-9f /* * Each body contains x, y, and z coordinate positions, * as well as velocities in the x, y, and z directions. */ typedefstruct { float x, y, z, vx, vy, vz; } Body; /* * Do not modify this function. A constraint of this exercise is * that it remain a host function. */ voidrandomizeBodies(float *data, int n){ for (int i = 0; i < n; i++) { data[i] = 2.0f * (rand() / (float)RAND_MAX) - 1.0f; } } /* * This function calculates the gravitational impact of all bodies in the system * on all others, but does not update their positions. */ voidbodyForce(Body *p, float dt, int n){ for (int i = 0; i < n; ++i) { float Fx = 0.0f; float Fy = 0.0f; float Fz = 0.0f; for (int j = 0; j < n; j++) { float dx = p[j].x - p[i].x; float dy = p[j].y - p[i].y; float dz = p[j].z - p[i].z; float distSqr = dx*dx + dy*dy + dz*dz + SOFTENING; float invDist = rsqrtf(distSqr); float invDist3 = invDist * invDist * invDist; Fx += dx * invDist3; Fy += dy * invDist3; Fz += dz * invDist3; } p[i].vx += dt*Fx; p[i].vy += dt*Fy; p[i].vz += dt*Fz; } } intmain(constint argc, constchar** argv){ /* * Do not change the value for `nBodies` here. If you would like to modify it, * pass values into the command line. */ int nBodies = 2<<11; int salt = 0; if (argc > 1) nBodies = 2<<atoi(argv[1]); /* * This salt is for assessment reasons. Tampering with it will result in automatic failure. */ if (argc > 2) salt = atoi(argv[2]); constfloat dt = 0.01f; // time step constint nIters = 10; // simulation iterations int bytes = nBodies * sizeof(Body); float *buf; buf = (float *)malloc(bytes); Body *p = (Body*)buf; /* * As a constraint of this exercise, `randomizeBodies` must remain a host function. */ randomizeBodies(buf, 6 * nBodies); // Init pos / vel data double totalTime = 0.0; /* * This simulation will run for 10 cycles of time, calculating gravitational * interaction amongst bodies, and adjusting their positions to reflect. */ /*******************************************************************/ // Do not modify these 2 lines of code. for (int iter = 0; iter < nIters; iter++) { StartTimer(); /*******************************************************************/ /* * You will likely wish to refactor the work being done in `bodyForce`, * as well as the work to integrate the positions. */ bodyForce(p, dt, nBodies); // compute interbody forces /* * This position integration cannot occur until this round of `bodyForce` has completed. * Also, the next round of `bodyForce` cannot begin until the integration is complete. */ for (int i = 0 ; i < nBodies; i++) { // integrate position p[i].x += p[i].vx*dt; p[i].y += p[i].vy*dt; p[i].z += p[i].vz*dt; } /*******************************************************************/ // Do not modify the code in this section. constdouble tElapsed = GetTimer() / 1000.0; totalTime += tElapsed; } double avgTime = totalTime / (double)(nIters); float billionsOfOpsPerSecond = 1e-9 * nBodies * nBodies / avgTime; #ifdef ASSESS checkPerformance(buf, billionsOfOpsPerSecond, salt); #else checkAccuracy(buf, nBodies); printf("%d Bodies: average %0.3f Billion Interactions / second\n", nBodies, billionsOfOpsPerSecond); salt += 1; #endif /*******************************************************************/ /* * Feel free to modify code below. */ free(buf); }
int bytes = nBodies * sizeof(Body); float *buf; cudaMallocHost((void **)&buf,bytes);
/* * As a constraint of this exercise, `randomizeBodies` must remain a host function. */ randomizeBodies(buf, 6 * nBodies); // Init pos / vel data float *d_buf; cudaMalloc((void **)&d_buf,bytes); Body *d_p=(Body *)d_buf;
/* * This simulation will run for 10 cycles of time, calculating gravitational * interaction amongst bodies, and adjusting their positions to reflect. */
/*******************************************************************/ // Do not modify these 2 lines of code. for (int iter = 0; iter < nIters; iter++) { StartTimer(); /*******************************************************************/
/* * You will likely wish to refactor the work being done in `bodyForce`, * as well as the work to integrate the positions. */
/* * This position integration cannot occur until this round of `bodyForce` has completed. * Also, the next round of `bodyForce` cannot begin until the integration is complete. */ integrate_position<<<block_num,block_size>>>(d_p,dt,nBodies);
/*******************************************************************/ // Do not modify the code in this section. constdouble tElapsed = GetTimer() / 1000.0; totalTime += tElapsed; }
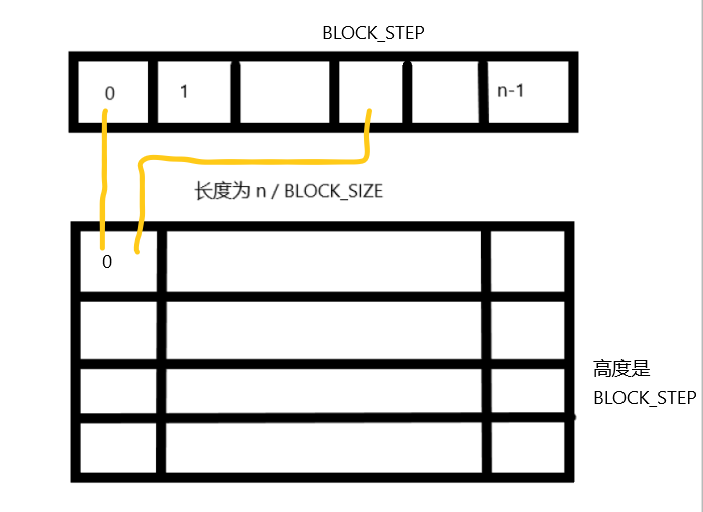
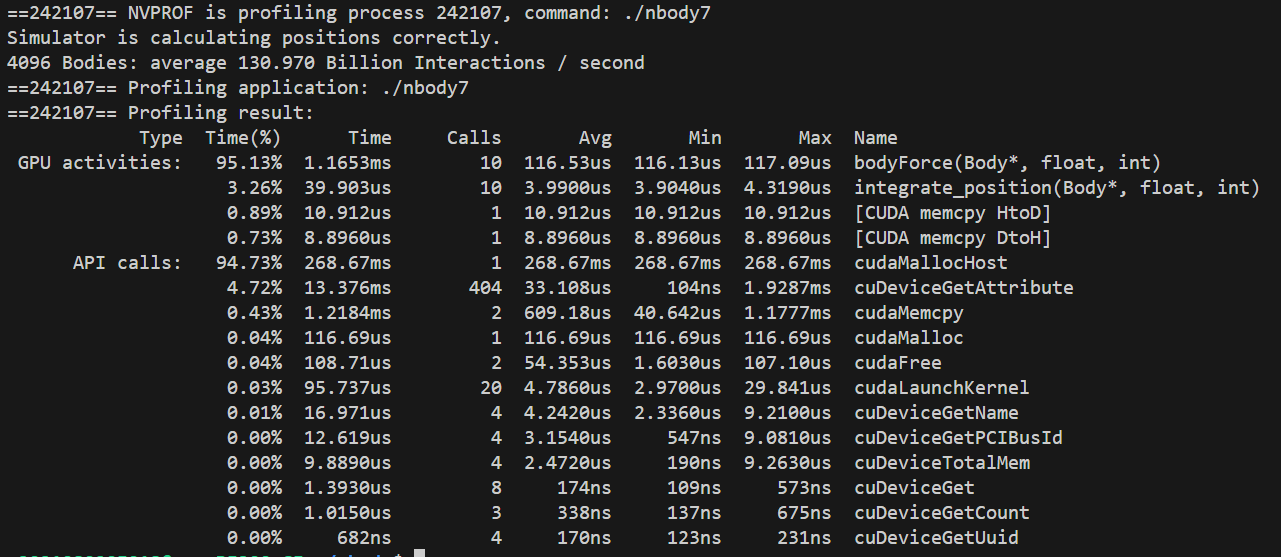
#define SOFTENING 1e-9f #define BLOCK_SIZE 32 #define BLOCK_STEP 32 /* * Each body contains x, y, and z coordinate positions, * as well as velocities in the x, y, and z directions. */
int bytes = nBodies * sizeof(Body); float *buf; cudaMallocHost((void **)&buf,bytes);
/* * As a constraint of this exercise, `randomizeBodies` must remain a host function. */ randomizeBodies(buf, 6 * nBodies); // Init pos / vel data float *d_buf; cudaMalloc((void **)&d_buf,bytes); Body *d_p=(Body *)d_buf;
/* * This simulation will run for 10 cycles of time, calculating gravitational * interaction amongst bodies, and adjusting their positions to reflect. */
/*******************************************************************/ // Do not modify these 2 lines of code. for (int iter = 0; iter < nIters; iter++) { StartTimer(); /*******************************************************************/
/* * You will likely wish to refactor the work being done in `bodyForce`, * as well as the work to integrate the positions. */
/* * This position integration cannot occur until this round of `bodyForce` has completed. * Also, the next round of `bodyForce` cannot begin until the integration is complete. */ integrate_position<<<block_num,BLOCK_SIZE>>>(d_p,dt,nBodies);
/*******************************************************************/ // Do not modify the code in this section. constdouble tElapsed = GetTimer() / 1000.0; totalTime += tElapsed; }